Information Technology Reference
In-Depth Information
2.2 Q-Learning Method
Reinforcement learning uses a trial and error method to learn how the agents
have to do the tasks. The agents interacts with the environment and receives
rewards or punishments depending on the actions result [8,6].
We use the Q-learning algorithm to identify the actions that the robots must
apply in each particular state in order to perform the task. We use the conven-
tional Q-learning update function [6,8]:
s
,a
)
−
Q
(
s, a
)
←
Q
(
s, a
)+
α
[
r
+
γmax
α
Q
(
Q
(
s, a
)]
(1)
2.3 States and Actions
To solve our problem we consider two different parts in the object:
P
and
P
.
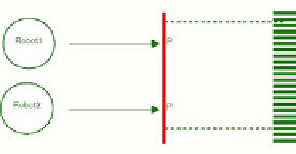
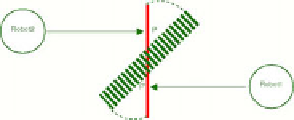
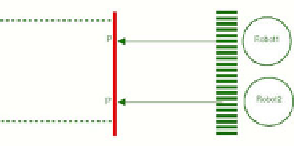
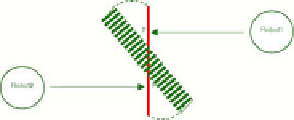
These parts define where the robots must push to move it. Figure 2 and figure 3
depict representation the object the differents movements of the object when the
robots push it. The grayed zone represents the object goal position. The circles
represents the robots. The arrows represent the robot's push movement.
Fig. 2.
Definition of states and actions. a) Decrease distance. b) P decrease, P' increase.
Fig. 3.
Definition of states and actions. a) Increase distance. b) P increase, P' decrease.
There are four different object movements according to where the robots push
it. If the two robots push to the same way, the object will advance or go back.
If the robots push it in the opposite sides the object turn to the left or to the
right over it self. So, if we consider these four kinds of movements we define four
states in our problem:
1. The distances between both
P
and
P
and the goal decrease. (Figure 2 a)
2. The distances between both
P
and
P
and the goal increase. (Figure 3 a)




Search WWH ::

Custom Search