Information Technology Reference
In-Depth Information
In the initial iterations, which are shown in the left side, the data items keep the
initial random order. According the algorithm operates, the data items begin
to keep together and the clusters start to appear. Around the 75 iteration —
approximately in the middle of the left diagram— the black and greys clusters
are almost clustered, just remain some data items belonged to these clusters
in the right side. The white cluster is divided into two noncontiguous clusters.
Around the 200 iteration the black cluster is completely formed and keeps in
such state until the end. The final tape's state, in which the data items are
grouped into the 4 existing clusters, is achieved in the iteration 283. Once the
convergence is reached, this state is maintained.
Afterwards an important post-processing step oriented to the automatic group-
ing of the data items scattered on the tape has to be applied.
As the data items are linearly grouped in the cellular automaton tape a
straightforward way of finding the natural clusters within the data is by an-
alyzing the chainmap diagram formed by the distances of the successive data
items. The main problem is to detect automatically the optimum threshold that
gives the correct number of clusters for each dataset.
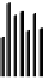
Fig. 5 displays the chainmap of the synthetic dataset in which it can be notice
the existence of 4 local maxima, each of one corresponding to an individual
cluster. These local maxima are located in the 20, 40, 60 and 80 bins. Notice
that the last one is needed for defining the the frontier between the last cluster
and the first one due to we are considering a toroidal lattice.
We have also employed the standard
k
-means clustering with this synthetic
dataset and we have achieved similar successful results for
k
=4.Asinour
proposed algorithm we have used the Euclidean distance as metric.
1.0
0.8
0.6
0.4
0.2
0.0
0
10
20
30
40
50
60
70
80
Fig. 5.
Chainmap of the synthetic dataset














































































Search WWH ::

Custom Search