Information Technology Reference
In-Depth Information
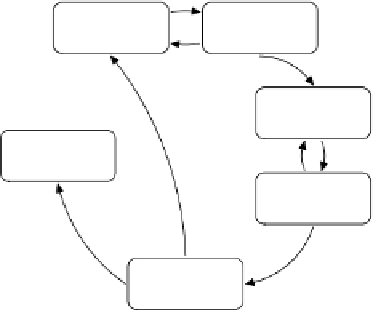
Fig. 1.
The phases of the CRISP-Data Mining process
the mining data. To be more concrete, he supposes that certain dependencies
may only hold true for a special model of car. Restricting the data to this model
means returning to data pre-processing and implies a rerun of preparation and
mining steps. Finally, it turns out that the analyst's guess was wrong. Although,
he laboriously restricted the data to different models, he was not able to capture
the dependency he expected. His next attempt is to take additional features of
the cars investigated into consideration, etc.
After a general search phase, typically the analyst begins to focus. This sec-
ond phase is characterized by trial and error and success depends largely on the
skills and experience of the analyst. Still the size of the generated rule sets is
problematic. Of course the search space is more and more restricted but normally
this effect is outbalanced by the lowered thresholds on the rule quality measures.
In addition a second problem nowbecomes obvious: investigating even specu-
lative ideas often implies a rerun of the mining algorithm and possibly of data
pre-processing tasks. Yet if every simple and speculative idea implies to be idle
for a fewminutes, then analysts will - at least in the long run - brake themselves
in advance instead of trying out diligently whatever pops into their minds. So,
creativity and inspiration are smothered by the annoying ine
-
ciencies of the
underlying technology. When mining for association rules on large datasets, the
response times of the algorithms easily range from several minutes to hours,
even with the fastest hardware and highly optimized algorithms available today,
c.f. [14].