Database Reference
In-Depth Information
A custom solution
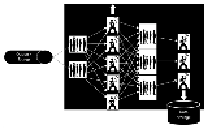
Here we talk about a solution that was used in the social media world before we had a scal-
able framework such as Storm. A simplistic version of the problem could be that you need
a real-time count of the tweets by each user; Twitter solved the problem by following the
mechanism shown in the figure:
Here is the detailed information of how the preceding mechanism works:
• A custom solution created a fire hose or queue onto which all the tweets are
pushed.
• A set of workers' nodes read data from the queue, parse the messages, and maintain
counts of tweets by each user. The solution is scalable, as we can increase the num-
ber of workers to handle more load in the system. But the sharding algorithm for
random distribution of the data among these workers nodes' should ensure equal
distribution of data to all workers.
• These workers assimilate this first level count into the next set of queues.
• From these queues (the ones mentioned at level 1) second level of workers pick
from these queues. Here, the data distribution among these workers is neither
equal, nor random. The load balancing or the sharding logic has to ensure that
tweets from the same user should always go to the same worker, to get the correct
counts. For example, lets assume we have different users— "A, K, M, P, R, and L"
and we have two workers "worker A" and "worker B". The tweets from user "A,
K, and M" always goes to "worker A", and those of "P, R, and L users" goes to
"worker B"; so the tweet counts for "A, K, and M" are always maintained by
"worker A". Finally, these counts are dumped into the data store.
The queue-worker solution described in the preceding points works fine for our specific
use case, but it has the following serious limitations:
• It's very complex and specific to the use case
Search WWH ::

Custom Search