Database Reference
In-Depth Information
The Hadoop solution
The Hadoop solution is one of the solutions to solve the problems that require dealing with
humongous volumes of data. It works by executing jobs in a clustered setup.
MapReduce is a programming paradigm where we process large data sets by using a map-
per function that processes a key and value pair and thus generates intermediate output
again in the form of a key-value pair. Then a reduce function operates on the mapper output
and merges the values associated with the same intermediate key and generates a result.
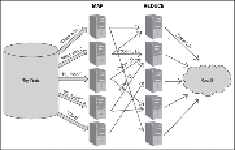
In the preceding figure, we demonstrate the simple word count MapReduce job where the
simple word count job is being demonstrated using the MapReduce where:
• There is a huge Big Data store, which can go up to zettabytes or petabytes.
• Input datasets or files are split into blocks of configured size and each block is rep-
licated onto multiple nodes in the Hadoop cluster depending upon the replication
factor.
• Each mapper job counts the number of words on the data blocks allocated to it.
• Once the mapper is done, the words (which are actually the keys) and their counts
are stored in a local file on the mapper node. The reducer then starts the reduce
function and thus generates the result.
• Reducers combine the mapper output and the final results are generated.
Big data, as we know, did provide a solution to processing and generating results out of hu-
mongous volumes of data, but that's predominantly a batch processing system and has al-
most no utility on a real-time use case.
Search WWH ::

Custom Search