Database Reference
In-Depth Information
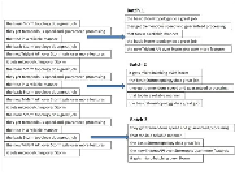
In the preceding figure, we have given a clear demonstration for micro-batching, how
small batches are created over the streaming data by the Trident framework in Storm.
Please remember, the preceding figure is just an illustration of micro-batching; the actual
number of tuples in a batch is dependent on the tps of the incoming data on the source and
is decided by the framework.
Now having achieved the micro-batching part of the problem, let's move on to the next
part of the problem that is executing distributed queries on these micro batches. Trident
Storm guarantees these queries to be low latency and lightning fast. In processing and se-
mantics, these queries are very much like
Remote Procedure Call
(
RPC
), but the distinc-
tion of Storm is that it gets you a high degree of parallelism, thus making them high per-
formance and lightning fast in their execution.
Let's have a look at integration of such DRPC-based queries with our Trident components.
The following is a code snippet for DRPC followed by an explanation:
myTridentTopology.newDRPCStream("words")
.each(new Fields("args"), new Split(), new Fields("word"))
.groupBy(new Fields("word"))
.stateQuery(wordCounts, new Fields("word"), new MapGet(),
new Fields("count"))
.each(new Fields("count"), new FilterNull())
.aggregate(new Fields("count"), new Sum(), new
Fields("sum"));
In the preceding code snippet, we created a DRPC stream using
myTridentTopology
and over and above it, we have a function named
word
.
Search WWH ::

Custom Search