Database Reference
In-Depth Information
Chapter 4
Understanding the BigQuery Object Model
To understand how to use BigQuery, it is helpful to know a bit about the
principal abstractions that it uses and a little bit of terminology. This chapter
explains the key objects used by BigQuery and establishes a language for
talking about them, which will be useful in subsequent chapters.
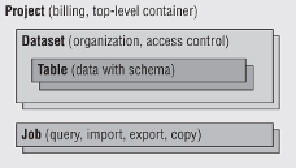
BigQuery is a structured data store; that is, it divides data into rows and
columns. A collection of rows of data is called a
table
, just like in any
relational database. Tables have a
schema
describing the columns of data
they contain. Tables are grouped into
datasets
, which are logical collections
of tables that can be shared. Datasets are owned by
projects
, which control
billing and serve as a global namespace root, meaning all of the object names
in BigQuery are relative to the project. Finally, all asynchronous operations
BigQuery performs on behalf of users are done via
jobs
.
Figure 4.1
shows
the relationship between the primary BigQuery abstractions. This chapter
describes these in more detail, starting with projects, then delving into data,
and finishing up with jobs and what BigQuery can do with your data.
Figure 4.1
BigQuery API abstractions
Projects
You've already seen and created a project in Chapter 3, “Getting Started
with BigQuery,” but what is a project exactly? Projects combine a number
of somewhat disparate functions—naming, billing, and access control—into
a single entity. Projects are managed via the Google Developers Console
location to control access to Google APIs. For the most part, after a project