Database Reference
In-Depth Information
option. With the GCS option you need to specify a bucket. You are not
restricted to a top-level bucket; you can specify a path within the bucket. It
is helpful to specify a unique path for each backup because it makes it much
simpler to locate the files when you have many backups. This is especially
important when loading the backup into BigQuery because you need to pass
the name of the backup file in the load job configuration. After the form is
complete, click the Backup Entities button to initiate the backup. You will
be taken to a page where you can monitor the underlying MapReduce job
performing the snapshot. If you go back to the Datastore Admin page, you
see the backup you scheduled either in pending or completed state. When a
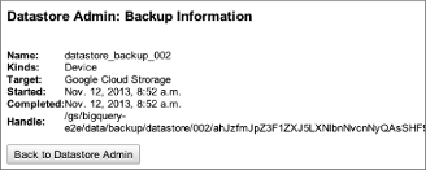
backup is complete you can select the backup and click information to see
the details of the backup as shown in
Figure 11.3
.
Figure 11.3
Datastore backup information page
The piece of information you are interested is the
Handle
, which is
effectively the location of the backup. In practice it is easier to locate the
relevant files using
gsutil
, for example:
$
gsutil ls gs://bigquery-e2e/data/backup/datastore/
001/*.backup_info
We have made a couple of backups from the sample application world
readable so that you can try the BigQuery commands even if you do not
set up your own copy of the AppEngine sample application. Running the
command previously shown lists two files of the form:
gs://bigquery-e2e/data/backup/datastore/
001/
handle
.Device.backup_info
gs://bigquery-e2e/data/backup/datastore/
001/
handle
.backup_info