Database Reference
In-Depth Information
goal of these two approaches is the same, but a hash partitioning is less work
than a sort.
The way the hash partitioning works is that each value is assigned a key.
A hash function is applied in a source shard to the key to turn it into a
number. That number, the hash code, is used to assign the entire row to a
destination shard. The source shard then sends the row over to the network
to the assigned destination shard. Because the workers are assigned stable
ranges of the hash key space, a single worker gets all the values that have the
same key.
For
GROUP EACH BY
operations, the shuffle key is the field or fields used
for the grouping. That is, if you do a
GROUP EACH BY corpus
on the
Shakespeare table, all the rows that have
Hamlet
as the corpus hash to the
same value and are sent to the same shard. All the rows that have the corpus
of
Macbeth
will hash to a different value, so they will be sent to a different
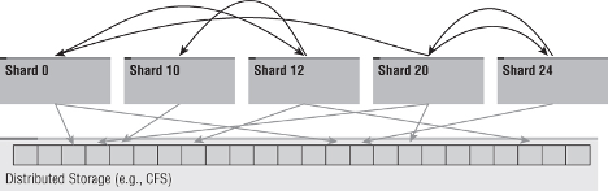
works. Each shard first reads the data from storage, then forwards that data
on to a diferent shard depending on the value of the shuffle key.
Figure 9.4
Shuffle operation
This same trick also works for
JOIN
, but both sides of the
JOIN
need to be
shuffled. To specify a shuffled
JOIN
, you can use the syntax
JOIN EACH
where you would otherwise have used
JOIN
, as in
LEFT OUTER JOIN
EACH
. The shuffle key is the field or fields used in the
ON
clause. That
is, if your query looks like
JOIN EACH . . . ON left.key1 =
right.key2
, the left table is shuffled by the
key1
field, and the right table
is shuffled by the
key2
field. Since the same hash function is used on both,
all of the rows with matching values from either table will end up in the