Database Reference
In-Depth Information
the sum of a few values (one value per shard). Performing more work in the
shards means that the query can scale out efficiently.
This mechanism just described—shards reading the raw table data and
performing filters and partial aggregation, and then passing results up to
a mixer that does further aggregation—is the basis of how Dremel works.
Each aggregation method, from
COUNT()
to
SUM()
to
STDDEV()
, and so
on, can be partitioned into parallel operations that can be combined into a
final result or results. Operations like
GROUP BY
, as well, can be partially
performed in the shards and subsequently combined in the mixer.
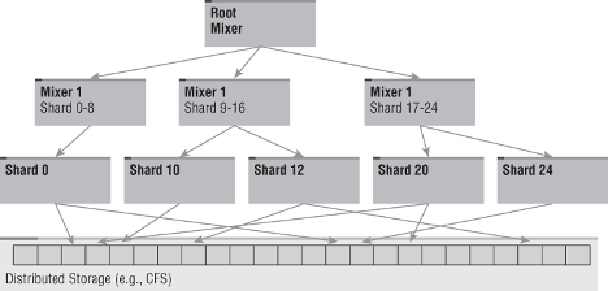
In a typical Dremel tree, there are hundreds or thousands of shards. Because
aggregating the results from all these shards is more work than a single
mixer could handle, the mixers are arranged in a tree. At the root of the tree
is the root mixer, which is responsible for responding back to the caller with
the result data.
Figure 9.2
shows a Dremel tree with two levels of mixers.
Figure 9.2
Dremel serving tree
Basic Queries
To help you understand how Dremel works, this section looks at a few
queries and walks you through how they are executed. For clarity in these
examples, we only describe the operations of a single mixer. When there
are multiple levels of mixers, they just repeat the same operations, so if you
understand how one works, you understand how a tree of them works. These
queries all use the
publicdata:samples.shakespeare
table which
contains counts for each word used in each Shakespeare play.