Information Technology Reference
In-Depth Information
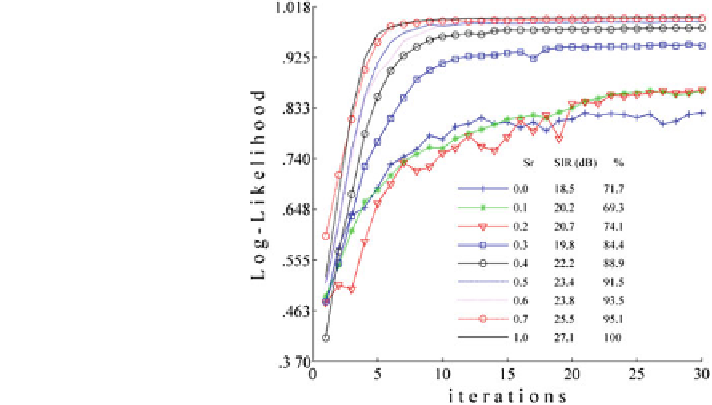
Fig. 3.5 Data log-likelihood
evolution through non-
parametric Mixca iterations.
Sr supervision ratio, SIR
signal-to-interference ratio, %
classification accuracy
Figure
3.5
shows the results of the first experiment. Different graphs of the
mean data log-likelihood evolution through the Mixca procedure iterations that
correspond to the supervision ratios used in the training stage are depicted. The
curves present an ascending behaviour with an increasing number of iterations; the
adjusted parameters fit the observed data and the log-likelihood is maximized.
The convergence of the algorithm depended on the supervision ratio, the over-
lapping areas of the classes, and the parameter initialization. The algorithm
converged successfully in 99.7 % of the cases in less than 30 iterations obtaining
different values of log-likelihood depending on the supervision ratio (values of
log-likelihood are normalized in Fig.
3.5
). The higher the values of supervision,
the higher the values of log-likelihood obtained. The non-convergence cases (when
the algorithm became stuck in a local maximum) corresponded to the lowest
supervisions (0, 0.1); after labelling some of the data, the algorithm converged to
the correct solution. In real application contexts, when there are enough historical
data, this will not be a problem.
The results of Fig.
3.5
can be grouped into two sets: middle- and high-log-
likelihood results. The results of log-likelihood were consistent with the results of
BSS and classification. Thus, the higher the log-likelihood value, the higher SIR
and the higher the classification accuracy. The graphs corresponding to the lowest
sr (0, 0.1, 0.2) showed oscillating patterns, while the graphs of the highest sr
(
0
:
3) were smooth and increased monotonically with a few exception points.
Thus, the uncertainty of the convergence was higher for the lowest supervisions. In
addition, convergence velocity was higher for the highest supervisions,
approaching the global maximum faster. In the case of the lowest supervisions, the
algorithm slowly improved the data log-likelihood. Even though the algorithm
surpassed zones of several local maxima, it did not converge accurately to the
global maximum. Natural gradient with stepsize annealing improves the data log-
Search WWH ::

Custom Search