Database Reference
In-Depth Information
a human; the index helps SQL Server find the data faster than just reading
the pages until it finds the information it's looking for.
When you create an index, you define a key value, or a set of key val-
ues, that define how the data is separated. For example, when looking at
the index in the back of the topic, you are looking through the data alpha-
betically, by the first letters of the highest-level node. In this case, the key
value is the highest-level word, which is sometimes derived from the head-
ings and subheadings used in the topic. Similarly, when an index is defined
on a table, the index must be based on one (or more) columns that tell the
index how to arrange the lookups of the data. Unlike a book, a table can
have multiple indexes defined to satisfy different types of queries. This al-
lows us to define indexes in order to manage queries from different sys-
tems, or wildly different queries against the same data from the same system.
Types
Now that you've seen the very basic structure SQL Server uses for indexes,
let's get some context surrounding the kinds of indexes you will actually use
in your database. The two basic index types are clustered and nonclustered
indexes. All indexes that you define on your tables will be one of these two
types. Let's take a closer look.
Clustered Indexes
Clustered indexes
actually restructure the data on disk. That is, if you de-
fine a clustered index on a table, that table is no longer a heap, because it
is actually sorted by the key value you've given it. For example, let's look at
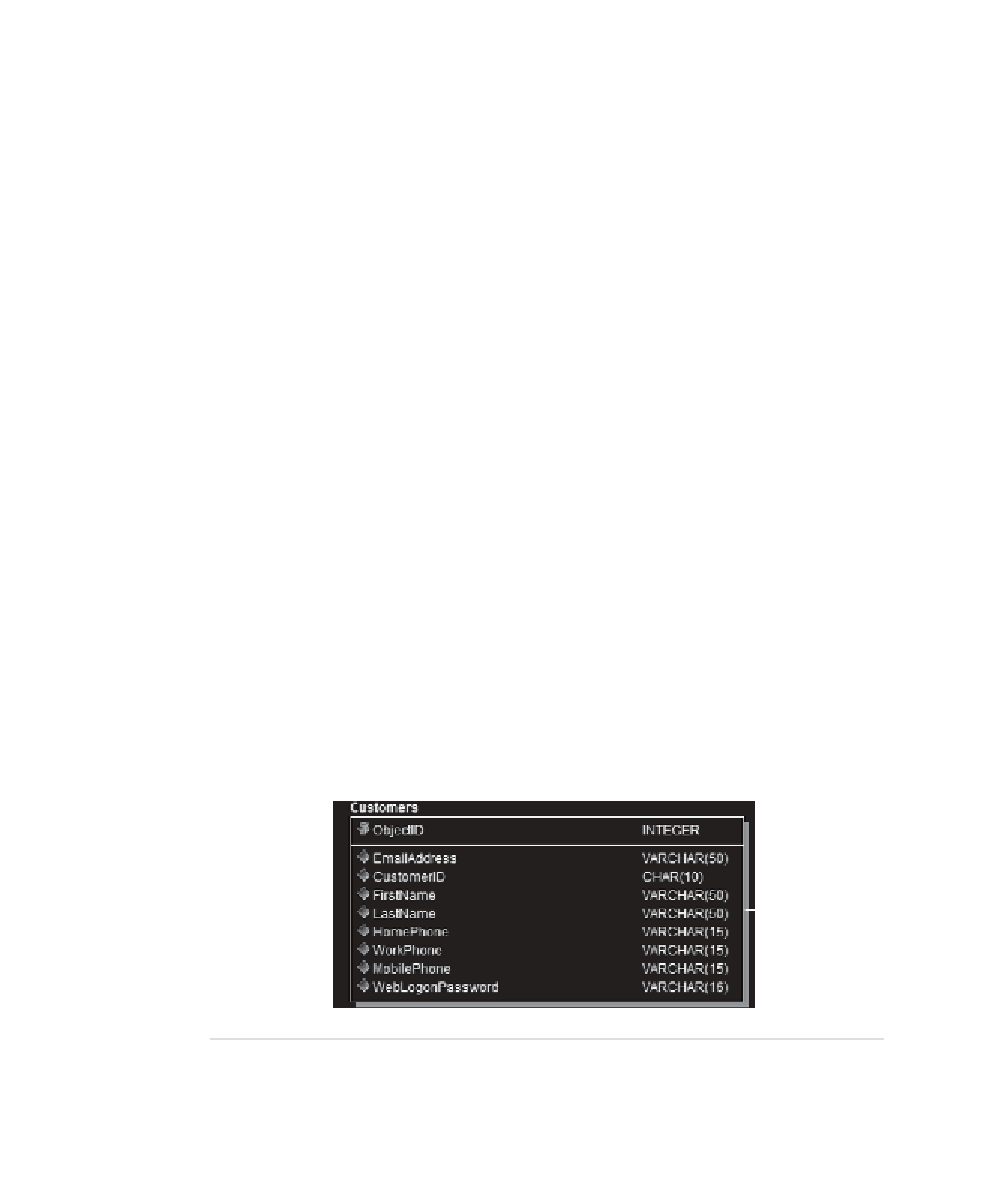
the Mountain View Music Customers table, as shown in Figure 10.2.
F
IGURE
10.2
Customers table for Mountain View Music
Search WWH ::

Custom Search