Information Technology Reference
In-Depth Information
case that the X-nodes are placed equidistantly on an optimal path from source to goal,
the complexity of PBA* is
⎛
n
X
⎞
(
)
Ob
⋅
2
+
1
⎜
⎟
⎜
⎟
⎝
⎠
where b is the branching factor of the problem (branching factor is the number of
nodes generated at any node expansion), n is the length of an optimal path from
source to goal, and |X| is the number of X-nodes (or islands). This situation is illus-
trated in Figure 3 for |X| = 2.
Fig. 3.
Algorithm PBA* in the best case
It can be shown (although the proof is not given in this paper) that the speedup of
PBA* over its uniprocessor version is potentially
linear on the number of processors
,
and the speedup of PBA* over the conventional uniprocessor A* algorithm is poten-
tially
exponential on the number of processors
. By “uniprocessor version of PBA*” it
is meant that algorithm PBA* is simulated on a uniprocessor machine. This can be
done, for example, by using a simulating program of a parallel machine running on a
uniprocessor (such programs may be provided by the manufacturer of the parallel
computer and are usually used for software development prior to porting to the actual
parallel machine), or by simply spawning processes in a multitasking operating sys-
tem like UNIX, or by utilizing the multithreading facility of modern programming
languages and operating systems.
In the general case where X-nodes are not placed equidistantly on an optimal path
from source to goal, the complexity of PBA* is
(
(
)
)
⎛
⎞
(
)
max
dist X
,
X
,
dist X
,
E
i
j
i
⎜
⎟
Ob
2
⎜
⎟
⎝
⎠
where
X
and
X
range over all X-nodes, and
E
is either the source or the goal
node. This situation is illustrated in Figure 4 for two X-nodes. There are two main
issues regarding the efficiency of PBA*. The first is search space management, that
is, how to efficiently detect intersections among the many search spaces. The second
is the X-node generation, that is, how to find X-nodes on a path from source to goal.



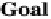
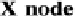
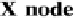







Search WWH ::

Custom Search