Database Reference
In-Depth Information
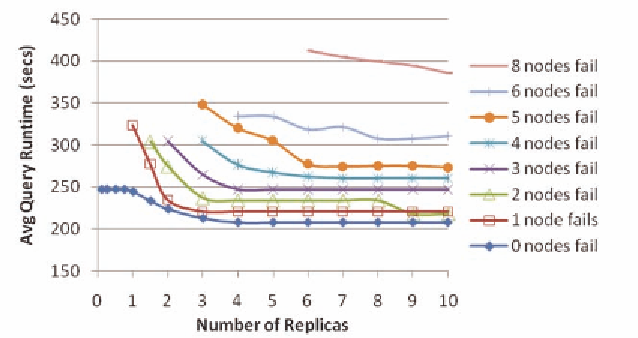
Figure 10. Availability analysis results
data allocation and replication alternatives that
ChunkSim implements and the analysis that
ChunkSim is currently able to run on performance
and availability features. We have used Chunksim
to analyze system size planning, peroformance
analysis of replication degree and availability
analysis, also comparing with results obtained in
an actual deployment on 16 nodes. These results
have shown that ChunkSim experiments can be
used to characterize the behavior of the system
with different placement and replication choices
and in the presence of node failures.The results
are also reasonably in aggreement with actual
runs on the prototype system.
There are several related issues that deserve fu-
ture work: in this work we assumed a star-schema,
with multiple small dimensions which are copied
into all nodes, and either a large fact (partitioned)
or a set of equi-partitioned relations (also denoted
as co-located). In the future ChunkSim should be
extended to handle query processing with non
co-located partitioned relations, in which case
the model should include repartitioning costs (the
costs from data exchange between nodes during
the processing of joins); The current ChunkSim
model assumes that every node sends its results to
a single merge node, which will merge the incom-
ing results from all nodes; We did not consider
failures in the merge and controller nodes. In a
future version of ChunkSim we expect to consider
redundant merge and controler nodes and to study
the impact of the additional overheads incurred in
these cases; In order to optimize processing over
a large number of nodes, it may be interesting to
explore hierarchical aggregation (Furtado 2005)
as well, whereby groups of nodes merge parts of
the partial results in parallel and send the results
to a next level in a hierarchical tree until a single
final node merges the partial results to form the
final result; In this setting, we also plan to consider
node failures within the merge hierarchy.
REFERENCES
Akal, F., Böhm, K., & Schek, H.-J. (2002).
OLAP Query Evaluation in a Database Cluster:
A performance study on intra-query parallelism.
East-European Conf. on Advances in Databases
and Information Systems (ADBIS), Bratislava,
Slovakia.
Bellatreche, L., & Boukhalfa, K. (2005).An evolu-
tionary approach to schema partitioning selection
in a data warehouse.
International Conference on
Data Warehousing and Knowledge Discovery
.
Search WWH ::

Custom Search