Database Reference
In-Depth Information
Figure 7. Determination of PIf
f
case chunks are placed automatically, according to
those numbers. Regardless of whether automatic
or manual data allocation was used initially, it is
always possible for the system administrator to
specify custom placements or modification of
current allocation using the (Pl-C) functionality.
Automatic placement refers to approaches
that determine chunk layouts automatically using
some simple heuristic. Homogeneous Placement
(Pl-H) refers to placing the same number of
chunks in every node. It is the simplest placement
alternative and has the merit that nothing is as-
sumed concerning the performance of different
nodes. A variation of homogeneous placement is
Homogeneous Size Placement (Pl-Hsz), where
placement targets similar total size of chunks
among nodes, as opposed to similar number of
chunks in Pl-H.
If WP statistics information is available, a
Performance-Wise Placement (Pl-W) solution can
be computed based on chunk processing times
and query frequencies:Average Composed Time
of Node j: ACT(N
j
)
=
the following algorithm from (Furatdo 2008)
achieves the objective shown in Figure 6.
If the performance indexes PI are all 1, the
result of Pl-W defaults to homogeneous placement
(Pl-H), and between (Pl-H) and (Pl-W) there is a
wide range of possibilities. In order to allow the
system administrator to choose these possibili-
ties, we add Performance Factor-wise placement
(Pl-Wf). This alternative uses a numeric factor
f
between 0 and 1 to smooth the weight of perfor-
mance indexes in the data allocation decisions,
therefore considering lower heterogeneity values
among nodes. Figure 7 summarizes how the new
performance factors are computed.
Given these modified performance factors,
the same algorithm 2 of Figure 6 is then applied
as for Pl-W.
Replica placement concerns how many copies
there will be for chunks and where those copies
will be placed. Custom replication (Rl-C) refers
to the system administrator specifying replicas
for individual chunks. Alternatively, it is possible
to specify automated replica placement, whereby
the system administrator specifies a replication
degree and policy.
Definition - Replication degree
: given a
data set D that is partitioned into Cc chunks and
placed into Nn nodes, the replication degree
r
is a
real number between 0 and N
n-1
determining how
nQueries
nChunks
å
å
f t(C QN)
i
´
l
i
j
i1
=
l1
=
Performance Index of Node j: PI
j
= ACT(N
j
)
/ max
j
{ACT(N
j
)}
Performance-wise placement places chunks in
nodes according to the performance indexes, that
is, nodes with higher performance indexes will
have more chunks. Given
i
å
PI
j
0
cumPIi
()=
,
j
=
Figure 6. Algorithm for performance-wise placement
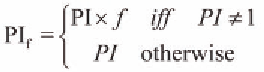

Search WWH ::

Custom Search