Database Reference
In-Depth Information
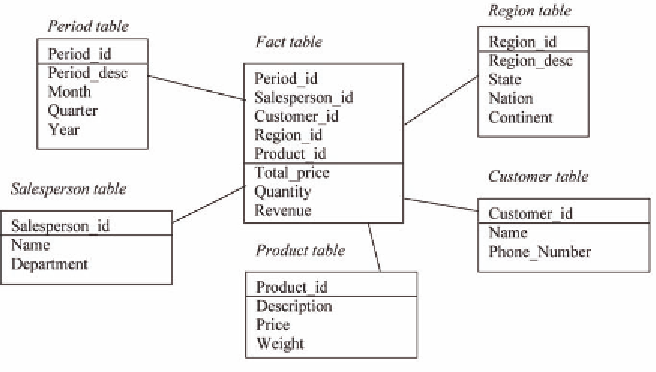
Figure 1. Sample DW Star schema
of an API for creating hypothetical indexes in a
DBMS, and the physical database design tool in
(Rao et al. 2002) tests hypothetical partitioning
alternatives to determine the most appropriate
configuration. In section 2.1 we review basic
partitioning and data allocation principles that
are useful in the SN context.
Given a data partitioning and allocation solu-
tion, query processing is also a most relevant issue,
which we review in section 2.2. In section 2.3 we
discuss replication and on-demand load-balancing,
which are used to enable optimized performance
and availability balancing.
very efficient partition-wise processing over star
schemas; The Node Partitioned Data Warehouse
(Furtado 2004, Furtado 2005, Furtado 2007)
uses heuristics for efficient workload-based
hash-partitioning in a shared-nothing environ-
ment; IBM shared-nothing approaches also use
workload-based hash-partitioning together with
what-if analysis, in order to determine the best
physical design solution (Rao et al. 2002); The
approach in (Bellatreche et al. 2005) proposes a
genetic algorithm for schema partitioning selec-
tion, whereby the fact table is fragmented based on
the partitioning schemas of dimension tables.
In this paper we assume a simple OLAP schema
context similar to the one assumed in (Sthor et al.
2000), and describe next a typical partitioning and
allocation scenario to help illustrate how it works:
In relational databases, data warehouses are fre-
quently organized as star schemas (Chaudhuri and
Dayal 1997), with a huge fact table that is related to
several dimension tables, as represented in Figure
1. In such schema, the fact tables (Sales fact in the
Figure) store data to be analyzed and pointers to
dimensions, while dimension information is stored
in dimension tables (the remaining relations).
It is frequent for dimension tables to be orders
of magnitude smaller than fact tables. When con-
Partitioning and Data Allocation
Automatic workload-based determination of parti-
tioning and indexing configurations was explored
in several works that include (Bellatreche et al.
2005, Furtado 2007, Rao et al. 2002, Sthor et al.
2000). Multi-Dimensional Hierarchical Fragmen-
tation (Sthor et al. 2000) uses workload-based
attribute-wise derived partitioning of facts and
in-memory retention of dimensions for efficient
processing, and introduces the use of join-bitmap
indexes together with attribute-wise derived
partitioning and hierarchy-aware processing for
Search WWH ::

Custom Search