Database Reference
In-Depth Information
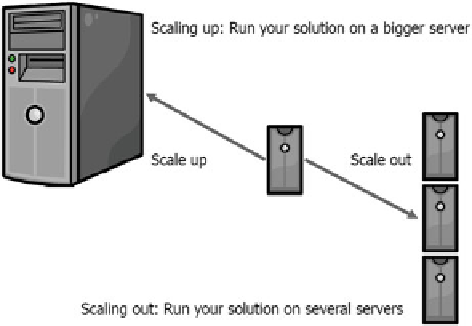
Fig. 3.1
Database scalability
options
billion of monthly active users and more than 140 billion friendship relationships.
Moreover, there are about 900 million objects that registered users interact with such
as: pages, groups, events and community pages. Other smaller scale social networks
such as Linkedin which is mainly used for professionals has more than 120 million
registered users. Twitter has also claimed to have over 500 million users. Therefore,
it becomes an ultimate goal to make it easy for every application to achieve such
high scalability and availability goals with minimum efforts.
Nowadays, the most common architecture to build enterprise Web applications
is based on a 3-tier approach: the Web server layer, the application server layer
and the data layer. In practice, data partitioning [
189
] and data replication [
160
]are
two well-known strategies to achieve the availability, scalability and performance
improvement goals in the distributed data management world. In particular, when
the application load increases, there are two main options for achieving scalability
at the database tier that enables the applications to cope with more client requests
(Fig.
3.1
)asfollows:
1.
Scaling up
: aims at allocating a bigger machine to act as database servers.
2.
Scaling out
:aimsat
replicating
and
partitioning
data across more machines.
In fact, the scaling up option has the main drawback that large machines are often
very expensive and eventually a physical limit is reached where a more powerful
machine cannot be purchased at any cost. Alternatively, it is both extensible and
economical—especially in a dynamic workload environment—to scale out by
adding storage space or buying another commodity server which fits well with the
new
pay-as-you-go
philosophy of cloud computing paradigm.
This chapter explores the recent advancements and the new approaches of the
Web scale data management. We discuss the advantages and the disadvantages
of each approach and its suitability to support certain class of applications and
end-users. Section
3.2
describes the NoSQL systems which are introduced and
used internally in the key players: Google, Yahoo and Amazon respectively.
Section
3.3
provides an overview of a set of open source projects which have
been designed following the main principles of the NoSQL systems. Section
3.4