Database Reference
In-Depth Information
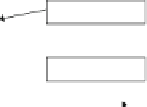
Fig. 9.17
Jaql system
architecture
Interactive Shell
Applications
Modules
Compiler
Script
Parser
Explain
Expr
Rewriter
Variables
Evaluation
MapReduce
I/O Desc
Value
Local
…
I/O Layer
File Systems
(hdfs, gpfs, local)
Databases
(DBMS, HBase)
Streams
(Web, Pipes)
local or distributed file systems (e.g., Hadoop's HDFS), database systems (e.g.,
DB2, Netezza, HBase), or from streamed sources like the Web. Unlike federated
databases, however, most of the accessed data is stored within the same cluster
and the I/O API describes data partitioning, which enables parallelism with data
affinity during evaluation. Jaql derives much of this flexibility from Hadoop's I/O
API. It reads and writes many common file formats (e.g., delimited files, JSON text,
Hadoop sequence files). Custom adapters are easily written to map a data set to
or from Jaql's data model. The input can even simply be values constructed in the
script itself. The Jaql interpreter evaluates the script locally on the computer that
compiled the script, but spawns interpreters on remote nodes using MapReduce.
The Jaql compiler automatically detects parallelization opportunities in a Jaql script
and translates it to a set of MapReduce jobs.
9.5
Conclusions
The database community has been always focusing on dealing with the challenges
of
Big Data
management, although the meaning of “
Big
” has been evolving
continuously to represent different scales over the time [
84
]. According to IBM, we
are currently creating 2.5 quintillion bytes of data, everyday. This data comes from
many different sources and in different formats including digital pictures, videos,
posts to social media sites, intelligent sensors, purchase transaction records and cell
phone GPS signals. This is a new scale of
Big Data
which is attracting a huge
interest from both the industrial and research communities with the aim of creating
the best means to process and analyze this data in order to make the best use of it.
In the last decade, the MapReduce framework has emerged as a popular mechanism
to harness the power of large clusters of computers. It allows programmers to think
in a
data-centric
fashion where they can focus on applying transformations to sets
of data records while the details of distributed execution and fault tolerance are
transparently managed by the MapReduce framework.
In this chapter, we presented a survey of the MapReduce family of approaches
for developing scalable data processing systems and solutions. In general we notice