Database Reference
In-Depth Information
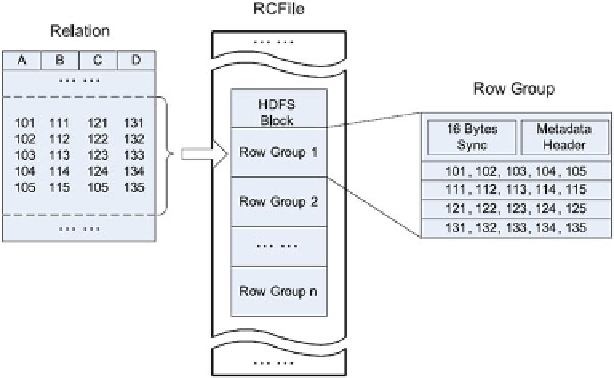
Fig. 9.8
An example structure of
RCFile
The notion of
Trojan Data Layout
has been coined in [
156
] which exploits the
existing data block replication in HDFS to create different Trojan Layouts on a per-
replica basis. This means that rather than keeping all data block replicas in the same
layout, it uses
different
Trojan Layouts for each replica which is optimized for a
different subclass of queries. As a result, every incoming query can be scheduled
to the most suitable data block replica. In particular, Trojan Layouts change the
internal organization of a data block and not among data blocks. They co-locate
attributes together according to query workloads by applying a column grouping
algorithm which uses an interestingness measure that denotes how well a set of
attributes speeds up most or all queries in a workload. The column groups are
then packed in order to maximize the total interestingness of data blocks. At query
time, an incoming MapReduce job is transparently adapted to query the data block
replica that minimizes the data access time. The map tasks are then routed of the
MapReduce job to the data nodes storing such data block replicas.
Effective Data Placement
In the basic implementation of the Hadoop project, the objective of the data
placement policy is to achieve good load balance by distributing the data evenly
across the data servers, independently of the intended use of the data. This simple
data placement policy works well with most Hadoop applications that access just
a
single
file. However, there are some other applications that process data from
multiple
files which can get a significant boost in performance with customized
strategies. In these applications, the absence of data colocation increases the data