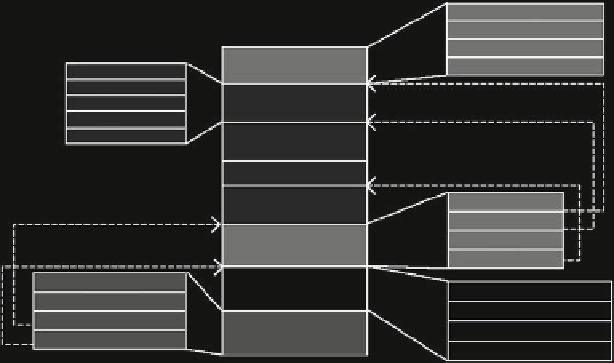
Database Reference
In-Depth Information
Version
Column Type
Compression Scheme
#value per block (k)
File Header
Sync (optional)
Value 1
Data Block 1
Value 2
...
Value k
Data Block 2
...
Data Block n
Offset of Block 1
Offset of Block 2
...
Block Index
Offset of Block n
Indexed Value
(Optional)
#Total records
#Blocks
Offset of Block index
Offset of Indexed Value
Starting value in Block 1
Starting value in Block 2
File Summary
...
Starting value in Block n
Fig. 9.7
An example structure of
CFile
1.
Compressed blocks
: This scheme uses a standard compression algorithm to
compress a block of contiguous column values. Multiple compressed blocks may
fit into a single HDFS block. A header indicates the number of records in a
compressed block and the block's size. This allows the block to be skipped if
no values are accessed in it. However, when a value in the block is accessed, the
entire block needs to be decompressed.
2.
Dictionary compressed skip list
: This scheme is tailored for map-typed columns.
It takes advantage of the fact that the keys used in maps are often strings that
are drawn from a limited universe. Such strings are well suited for dictionary
compression. A dictionary is built of keys for each block of map values and store
the compressed keys in a map using a skip list format. The main advantage of this
scheme is that a value can be accessed without having to decompress an entire
block of values.
One advantage of this approach is that adding a column to a dataset is not an
expensive operation. This can be done by simply placing an additional file for
the new column in each of the split-directories. On the other hand, a potential
disadvantage of this approach is that the available parallelism may be limited for
smaller datasets. Maximum parallelism is achieved for a MapReduce job when the
number of splits is at least equal to the number of map tasks.
The
Llama
system [
177
] have introduced another approach of providing column
storage support for the MapReduce framework. In this approach, each imported
table is transformed into column groups where each group contains a set of files
representing one or more columns. Llama introduced a column-wise format for
Hadoop, called
CFile
, where each file can contain multiple data blocks and each
block of the file contains a fixed number of records (Fig.
9.7
). However, the size of
each logical block may vary since records can be variable-sized. Each file includes