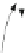Database Reference
In-Depth Information
Master
Slaves
Task11
Task12
Task13
Job 1
Job 2
Job 3
Task21
Task22
Task23
Task31
Task32
Task33
.
.
.
Task Scheduler
Task Tracker
Loop Control
Caching
Indexing
Task Queue
Distributed File System
Local File System
Local communication
Remote communication
Modified from Hadoop
Identical to Hadoop
New in HaLoop
Fig. 9.6
An overview of HaLoop architecture
The
HaLoop
system [
87
,
88
] is designed to support iterative processing on the
MapReduce framework by extending the basic MapReduce framework with two
main functionalities:
1. Caching the invariant data in the first iteration and then reusing them in later
iterations.
2. Caching the reducer outputs, which makes checking for a fixpoint more efficient,
without an extra MapReduce job.
Figure
9.6
illustrates the architecture of HaLoop as a modified version of the
basic MapReduce framework. In order to accommodate the requirements of iterative
data analysis applications, HaLoop has incorporated the following changes to the
basic Hadoop MapReduce framework:
It exposes a new application programming interface to users that simplifies the
expression of iterative MapReduce programs.
HaLoop's master node contains a new loop control module that repeatedly starts
new map-reduce steps that compose the loop body until a user-specified stopping
condition is met.
It uses a new task scheduler that leverages data locality.
It caches and indices application data on slave nodes. In principle, the task tracker
not only manages task execution but also manages caches and indices on the slave
node and redirects each task's cache and index accesses to local file system.
In principle, HaLoop relies on the same file system and has the same task queue
structure as Hadoop but the task scheduler and task tracker modules are modified,
and the loop control, caching, and indexing modules are newly introduced to the