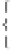Database Reference
In-Depth Information
the best is
2
ln
W
+
=
1
α
.
W
−
W
−
are, respectively, the sum of the weights of the
examples well and bad classified.
For the last question, how to train the base learner, it must be a multi-
class learner, and we want to use binary learners (only one literal). Then, for
each iteration, we train the weak learner using a binary problem: one class
(selected randomly) against the others. The output of this weak learner,
h
t
(
Where
W
+
and
x
) is binary. On the other hand, we do not generate a unique
α
t
, but
for each class,
α
tl
is selected. They are selected considering how
good is the weak learner for discriminating between the class
l
,an
and the
rest of classes. This is a binary problem so the selection of the values can
be done as indicated in [Schapire and Singer (1998)]. Now, we can define
h
t
(
l
α
tl
h
t
(
x, l
)=
x
)and
α
t
=1andweuseA
da
B
oost
.MH.
3. Interval Based Literals
Figure 2 shows a classification of the predicates used to describe the series.
Point based predicates use only one point of the series:
•
point le(Example, Variable, Point, Threshold)
it is true if, for the
Example
,
the value of the
Variable
at the
Point
is less or equal than
Threshold
.
Note that a learner that only uses this predicate is equivalent to an
attribute-value learning algorithm. This predicate is introduced to test the
results obtained with boosting without using interval based predicates.
Two kinds of interval predicates are used: relative and region based. Rel-
ative predicates consider the differences between the values in the interval.
Region based predicates are based on the presence of the values of a variable
in a region during an interval. This section only introduces the predicates
[Rodrıguez
et al.
(2001)] gives a more detailed description, including how
to select them eciently.
Point based:
point_le
Relative:
increases, decreases, stays
Predicates
Interval based
Region based:
Sometimes, always, true_percentage
Fig. 2.
Classification of the predicates.