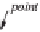Database Reference
In-Depth Information
Fig. 14. Performing unweighted and weighted matching in order to provide more accu-
racy in the matching between sequences.
The average length of the series is around 1100 points. The shortest one is
834 points and the longest one 1719 points.
To determine the eciency of each method we performed hierarchical
clustering after computing the
2 pairwise distances for all three
distance functions. We evaluate the total time required by each method, as
well as the quality of the clustering, based on our knowledge of which word
each sequence actually represents. We take all possible pairs of words (in
this case 5
N
(
N −
1)
/
2 = 10 pairs) and use the clustering algorithm to partition
them into two classes. While at the lower levels of the dendrogram the
clustering is subjective, the top level should provide an accurate division
into two classes. We clustered using single, complete and average linkage.
Since the best results for every distance function are produced using the
complete linkage
, we report only the results for this approach (Table 3,
Fig. 15). The same experiment is conducted with the rest of the datasets.
Experiments have been conducted for different sample sizes and values of
δ
∗
4
/
(as a percentage of the original series length).
The results with the Euclidean and the Time Warping distance have
many classification errors. For the
LCSS
the only real variations in the
clustering are for sample sizes
10% (Figure 16). Still the average incor-
rect clusterings for these cases were constantly less than 2 (
s ≤
<
1
.
85). For 15%
sampling or more, there were no errors.
6.2.3.
Experiment 2 — Australian Sign Language Dataset (ASL)
3
The dataset consists of various parameters (such as the X ,Y, Z hand
position, roll, pitch, yaw, thumb bend etc) tracked while different writers
3
http://kdd.ics.uci.edu