Information Technology Reference
In-Depth Information
analyzed data set and represents it in visually comprehensible lower-
dimensional space. Reduction of the original variables number results
from generation of their linear combinations - new latent variables (LV),
referred to as loadings.
Note that bold uppercase (e.g.
X
) represents matrices, bold lowercase
(e.g.
y
) represents vectors, and italic characters represent scalars.
X
T
indicates vector transpose, if:
[4.1]
[4.2]
The transpose of a column vector is a row vector and vice versa.
Inverse matrix of X is:
[4.3]
In the case of a data set of
M
samples and
N
variables (Figure 4.1, a
data set of 4 samples and 2 variables), each sample represents row vector
x
i
T
. Each variable
j
is described by its values for all samples with column
vector
x
j
. If sample vectors are plotted in variable space, then the number
of axes is equal to the number of variables
N
. This way, all the information
in
X
, regarding the relationships (similarities or differences) between
samples, can be displayed. The same stands for representation of variable
vectors in sample space. The number of axes is equal to the number of
samples and relationships (correlations or co-variances) between variables
(Rajalahti and Kvalheim, 2011). This common variation (i.e. correlation)
between variables is used to determine new LVs. An increase in the
number of variables studied complicates the determination of LVs, such
as dimensionality reduction. This task is usually achieved by projecting
onto LVs. One of the most common algorithms used for computation of
LVs is the non-linear iterative PALS (NIPALS) algorithm (Geladi and
Kowalski, 1986). The idea behind the NIPALS algorithm is successive
orthogonal projection of LVs. Prior to LV projection, weight vector
w
a
is
defi ned, on a different basis for different multivariate methods. The
weight vector describes LVs in both variable and sample space. Therefore,
the score vector
t
a
and loading vector
p
a
are different presentations of the
same LV, carrying information about samples in variable space and
variables in sample space, respectively (Rajalahti and Kvalheim, 2011).
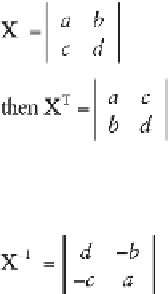



Search WWH ::

Custom Search