Information Technology Reference
In-Depth Information
elimination of unnecessary branches and decision nodes. Apart from
simplifi cation of the developed tree, this process also reduces the
possibility of tree overfi tting. The C5.0 algorithm is an improved version
of the C4.5 algorithm. More detailed explanations of algorithms can be
found in relevant textbooks (Quinlan, 1993; Mitchell, 1997).
Therefore, the main concern of every algorithm is to select the
appropriate splitting attribute in a decision node. Splitting criteria in
decision nodes are goodness functions and the best splitting attribute is
usually the one that results in the smallest tree. The goal is to select the
attribute that is most useful for classifying examples. The most frequently
used splitting criteria are information gain, gain ratio, and the Gini index.
Information gain criterion measures the node impurity, that is,
information gain increases with the average purity of the subsets that an
attribute produces. It measures how well a selected attribute separates
the data set samples according to their target classifi cation. Information
gain is therefore an expected reduction in entropy caused by partitioning
of the samples according to selected attribute:
[5.18]
where
Gain(S,A)
is the information gain of an attribute
A
relative to a set
of samples
S
,
Values(A)
is the set of all possible values for attribute
A
,
and
S
v
is the subset of
S
for which attribute
A
has value
v
. Entropy is a
measure of (im)purity of an arbitrary data set. Entropy can range from 0,
if all samples of the data set belong to the same class, to its maximum
value of 1. Maximal entropy in a classifi ed data set when there is the
same number of samples belonging to each class. The fi rst term in the
equation is the entropy of the original set of samples
S
:
[5.19]
where
p
i
is the proportion of samples belonging to class
i
and
c
stands for
the number of values that the target attribute can take. Binary logarithm
log
2
n is the logarithm to the base 2. Information entropy involves the
binary logarithm; this is needed because the unit of information, the bit,
refers to information resulting from an occurrence of one of two equally
probable alternatives (sample belongs to the class or do not). The second
term of the equation is the expected value of the entropy after
S
is
partitioned using attribute
A
. It is the sum of the entropies of each subset,
S
v
, weighted by the fraction of samples |
S
v
|/|
S
| that belongs to
S
v
.
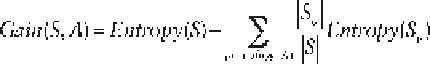




Search WWH ::

Custom Search