Information Technology Reference
In-Depth Information
[5.11]
where the distance
D
between the training sample and the point of
prediction is used to measure how well each training sample can represent
the position of prediction:
[5.12]
using the standard deviation or the smoothness parameter, σ (Specht,
1991).
The process of GRNN training is very fast. Furthermore, training of
the GRNN differs from classical neural networks in that every weight is
replaced by a distribution of weights (Takagaki et al., 2010).
Radial basis functions were introduced in the fi eld of neural networks
by Broomhead and Lowe (1988). The
Radial Basis Function Neural
Network (RBFNN)
uses Gaussian activation functions, whose parameters
are adjusted during the training process. This network performs more
localized adaptation than other types of neural network. The hidden
layer in RBFNN is composed of radial basis functions units and each
radial basis function unit has a built-in distance criterion with respect to
a center (Lim et al., 2003). In this way, the network is made advantageous
because it does not get stuck in local minima during optimization.
Training is performed by a competitive algorithm, where the weight
vectors are moved in the direction of the input vectors, thus fi nding
clusters in the data (multiple inputs and weights are referred to as vector
coordinates). The output layer performs a linear combination of the
outputs from the basis nodes (Lim et al., 2003):
[5.13]
where
h
is the number of units (neurons) in the hidden layer, and vector
a
refers to the distance of the input vector
x
to each of the centers in the
hidden layer. Generally, the Euclidian norm is used to compute the
distance:
[5.14]
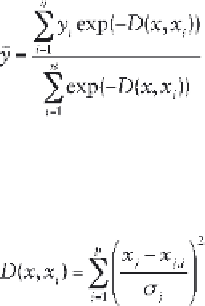
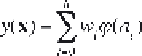
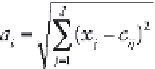




Search WWH ::

Custom Search