Information Technology Reference
In-Depth Information
weight values is found, the network training stops and the squared error
between the actual (training) output values and those predicted by the
network is minimal at this point. At the beginning of the training process,
data are divided in two subsets, training and test. Training data are used
to search for optimal weight values, whereas by using the test data, the
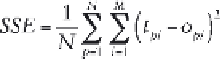
network checks its predictive ability externally. The sum of squared
errors (SSE) for the training and test subsets can be calculated using the
following equation (Basheer and Hajmeer, 2000):
[5.3]
where
o
pi
is the output predicted by the network of
i
th output node from
the
p
th sample;
t
pi
is the training (actual) output of the
i
th output node
from the
p
th sample;
N
is the number of the training samples; and
M
is
the number of the output nodes.
In the process of network training, the progress of change of error for
training and test data sets are evaluated simultaneously. In the case of a
training data set, SSE decreases indefi nitely with the increasing number of
hidden nodes or training iterations (epochs) (Sun et al., 2003). Initially,
SSE for the training set decreases rapidly due to learning, whereas its
subsequent slower decrease is attributed to memorization or overfi tting
(if the number of training cycles or hidden nodes is too large). In the test
data set, SSE decreases initially, but subsequently increases due to
memorization and overfi tting of the ANN model (Sun et al., 2003). It is
therefore recommended to stop the training once the test error starts to
increase and to select the number of hidden nodes when the test error is
at a minimum (Sun et al., 2003).
Training data can be presented to the network model by example
(incremental training) or as the whole batch (batch training) (Wythoff,
1993). The weights are updated after processing each sample for the
incremental training process or after processing the entire training set for
the batch training process (Sun et al., 2003).
The training process can be set up to last until the predetermined error
value is found, or for a certain period of time. It is important to note that
in the case of neural networks, error is minimized in terms of the weights
of the network rather than in terms of the parameters, as is the case of
least-squares methods in conventional statistical approaches (Reis et al.,
2004).
One of the most commonly used training methods (i.e. weight
adjustment method) is the
back-propagation (BP) algorithm
(McClelland




Search WWH ::

Custom Search