Information Technology Reference
In-Depth Information
Fig. 12.20
Value-based ranking
RV
(the higher the better) for each dataset separately, for
DSIM
measure only with local image descriptors included
Table 12.8
Relative differences (%) between aggregation measures calculated for both datasets as
wholes and the measures based on mean values of subsets
Visual descriptor
External stability
Value-based ranking
Position-based ranking
SE
difference (%)
RV
difference (%)
RP
difference (%)
9.8
−
6.5
−
17.6
CLD
CLDTrans
12.2
−
3.7
−
6.5
7.5
−
9.3
−
10.0
EHD
15.4
−
3.7
−
5.9
CMSP
−
−
Hist
8.0
0.2
3.4
5.7
−
12.9
9.7
HistFull
14.6
−
14.9
4.7
LBPHist
−
MomentCentNorm
27.9
20.1
22.9
−
3.0
−
0.1
3.6
MomentInvGPSO
VertTrace
6.0
−
9.1
0.0
stant for all vehicles (e.g. borders between windows and a vehicle body); there is much
more diversity in case of human images. For HUMAN set, the
OpponentSift
descriptor (the best one of all local image features) occupies the third place.
In the last experiments, it was evaluated how the results calculated for each subset
of both datasets independently correlate with results based on the whole sets (Table
12.8
). It may be noticed that for majority of descriptors, external stability
SE
is lower
(stability value is higher) which seems to be obvious because of a larger quantity of
objects in the dataset. At the same time, value-based ranking
RV
values decreased
which means that descriptor evaluation measures vary more. However, in majority
of cases, difference values are less than 10 %. It proves that the results presented in
the chapter are invariant to the number of objects in datasets.
Table
12.9
contains proposed visual descriptors that are better than others (both
in case of their effectiveness and stability) for each dataset independently and for
both datasets simultaneously. These features are characterized by the highest rank-









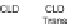





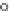
































































Search WWH ::

Custom Search