Information Technology Reference
In-Depth Information
is, on average, present in time-series data to a lower extent than in text or images [
49
]
where these methods were previously shown to perform rather well.
On the other hand, HIKNN, the information-theoretic approach to handling vot-
ing in high-dimensional data, clearly outperforms all other tested methods on these
time series datasets. It performs significantly better than the baseline in 19 out of
37 cases and does not perform significantly worse on any examined dataset. Its
average accuracy for
k
10 is 84.9, compared to 82.5 achieved by
k
NN. HIKNN
outperformed both baselines (even though not significantly) even in case of the
ChlorineConcentration dataset, which has very low hubness in terms of skewness,
and therefore other hubness-aware classifiers worked worse than
k
NN on this data.
These observations reaffirm the conclusions outlined in previous studies [
50
], arguing
that HIKNN might be the best hubness-aware classifier on medium-to-low hubness
data, if there is no significant class imbalance. Note, however, that hubness-aware
classifiers are also well suited for learning under class imbalance [
16
,
20
,
21
].
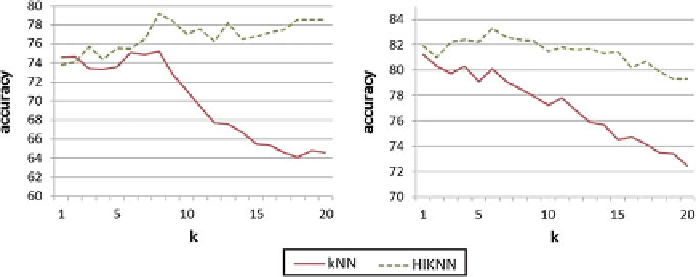
In order to show that the observed improvements are not merely an artifact of
the choice of neighborhood size, classification tests were performed for a range of
different neighborhood sizes. Figure
11.8
shows the comparisons between
k
NN and
HIKNN for
k
=
, on Car and Fish time series datasets. There is little difference
between
k
NN and HIKNN for
k
∈[
1
,
20
]
1 and the classifiers performance is similar in
this case. However, as
k
increases, so does the performance of HIKNN, while the
performance of
k
NN either decreases or increases at a slower rate. Therefore, the
differences for
k
=
20 are even
greater. Most importantly, the highest achieved accuracy by HIKNN, over all tested
neighborhoods, is clearly higher than the highest achieved accuracy by
k
NN.
These results indicate that HIKNN is an appropriate classification method for
handling time series data, when used in conjunction with the dynamic time warping
distance.
Of course, choosing the optimal neighborhood size in
k
-nearest neighbor methods
is a non-trivial problem. The parameter could be set by performing cross-validation
on the training data, though this is quite time-consuming. If the data is small, using
=
10 are more pronounced and the differences for
k
=
Fig. 11.8
The accuracy (in %) of the basic
k
NN and the hubness aware HIKNN classifier over a
range of neighborhood sizes
k
∈[
1
,
20
]
, on Car and Fish time series datasets

Search WWH ::

Custom Search