Information Technology Reference
In-Depth Information
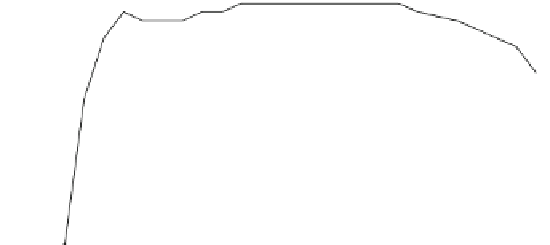
Fig. 5.3
ANN classification accuracy observed in sequential backward elimination process, in
relation to the number of considered features, for each average there is indicated maximal and
minimal performance
on examples, the full algorithm with hard constraints on minimal rule support gives
much better results of 76.67%. Yet this full algorithm contains over 46 thousands of
constituent decision rules and calculation takes a noticeable amount of time. Genera-
tion of this type of algorithm at all stages of backward elimination of features would
be far too much time-consuming. Instead, another approach is employed, focused on
the previously inferred all rules on examples algorithm for the entire set of attributes.
Decision rules included in the full algorithm have varying lengths equal to
the numbers of conditions in the premise part, varying supports, refer to various
attributes. If we were to employ backward elimination procedures and attempted to
induce all rules on examples algorithms for subsets of variables in subsequent reduc-
tion stages it is reasonable to expect that at least a part of newly inferred rules would
be the same as those already found. Therefore, rather than waste time on such simply
repetitive computations we can apply the backward selection to the full algorithm
itself in the following manner.
In the first step we disregard all rules with conditions on a specific variable, itera-
tively for all variables. As a result we obtain 25 different reduced decision algorithms,
which are then tested and the one with the highest classification accuracy is selected.
We reject the attribute, elimination of which have resulted in this algorithm, and use
this limited set of decision rules as the input to the second stage of processing, where
24 reduced algorithms are tested, and so on, with reduction of one feature and all
rules referring to it at each stage. The process can continue till the point of detecting
some significantly worse performance, rejecting all rules from the algorithm (even
though there are still some features left to be considered), or reducing all conditional
attributes. With this last stopping criterion there is obtained weighting of variables
which can be used for other purposes. The procedure of discarding rules governed
by included attributes can be perceived as rule filtering.
The detailed results from execution of described methodology are shown in
Table
5.3
, in which the ranking of features is given in the (h) column.


















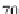


































































































Search WWH ::

Custom Search