Information Technology Reference
In-Depth Information
types, corresponding to different chemical structures (labeled as (A, C, D, E,
F, G, H, I, K, L, M, N, P, Q, R, S, T, V, W, Y)). The main and side chains
in a protein are shown in an example in Fig. 3B. Side-chains themselves have
components in common among each other based on their chemical composition.
Thus, we could also consider smaller chemical units than the amino acids as the
functional building blocks of proteins. This would correspond to the vocabulary
shown in Fig. 4. These are in fact more fundamental units than the amino acids
themselves, because mutations, i.e. replacements of amino acids in protein se-
quences, that only exchange one single chemical group, e.g. from phenylalanine
to tyrosine (OH group) can have detrimental effects on protein function.
At the other end, there are also cases where a single amino acid is not su-
cient to convey a specific “meaning”, but a group of amino acids does, generally
referred to as a functional motif. For example, the triplet D/E R Y is a conserved
motif in a specific protein family (the G-protein coupled receptors) known to en-
code the ability to interact with another protein (the G-protein). Finally, amino
acid sequences can be replaced without loss in function, as individual amino
acids or as groups of amino acids. For example, in the above triplet, the first
position is not fully defined - it can be either D or E. This is due to the chemical
nature of the amino acids: D and E although having different side chains, share
a number of properties, most importantly, negative charge in this case. Thus,
the biological vocabulary is much more flexible than the human vocabulary, be-
cause it is defined through properties with several different chemical meanings
and not a single meaning as in the case of the 26 letters. There are hundreds of
different scales of properties of amino acids, including size, hydrophobicity, elec-
tronic properties, aromaticity, polarity, flexibility, secondary structure propen-
sity and charge to name just a few (see e.g., the online databases PDbase [20]
and ProtScale [21]). Thus, although the 20 amino acids are a reasonable starting
point to define building blocks in protein sequences, smaller, larger or uniquely
encoded units may often be functionally more meaningful.
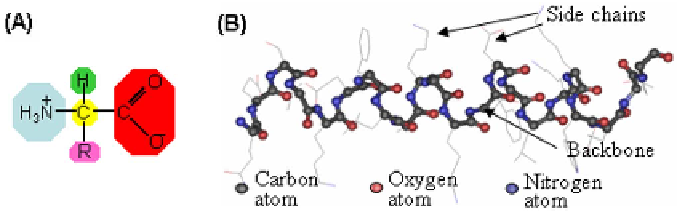
Fig. 3.
(A) Chemical composition of amino acids. The composition common to all
amino acids consists of a main carbon atom
C
α
(yellow), NH
3
group (blue), carboxyl
group COO- (red), hydrogen atom (green) and a sidechain R (pink). The first three,
along with the
C
α
, are common to all amino acids, where as the side chain R is
different for each amino acid [17]. (B) Protein segment. A small protein segment with
the composing main chain atoms is shown in ball-and-stick model. Side chains attached
to the
C
α
are shown in grey wire frame.
Search WWH ::

Custom Search