Information Technology Reference
In-Depth Information
windows, make the segmentation problem more dicult. We chose to apply the
Oc1
method [54], as implemented in the MLC++ library [39]. To learn the model,
we built a database of 50,000 entries, each pixel being labeled as “wooden door”
or “rest”. No more precise division is needed, due to the fact that the only goal
at this stage is to be able to distinguish the wooden door from the other surfaces
in the robot's environment. To obtain this database, we processed sixty images
taken by the robot, in which the relevant elements of its environment appeared.
We cut these images into 395 slices, each representative of one and only one of
the different surfaces, labeling these pixels manually. With this procedure, we
obtained a large database of more than 4,000,000 labeled pixels. From this huge
set, we randomly selected 50,000 to build a training set of 40,000, from which
the model is learned, and a test set of 10,000, to test the accuracy of the model.
This procedure was repeated ten times, obtaining a mean accuracy over 97%.
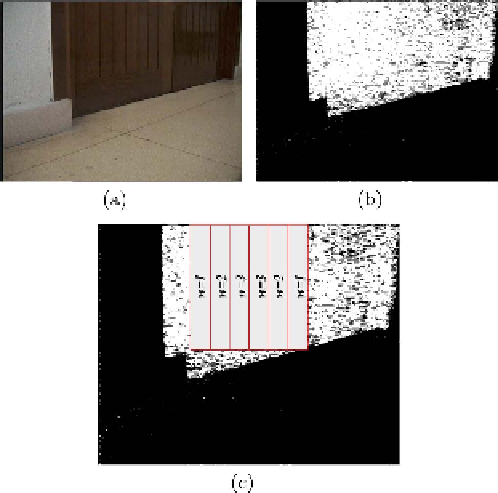
Figure 3 shows an example of the result given by the segmentation process.
In order to decide whether the robot is in front of a door or not, we take into
account that, when the camera's tilt angle is appropriately set, the door always
fills the upper half of the image, so the floor may appear in the lower half. It
is then enough to process only the rows in the upper half in order to make a
decision. If the robot is in front of a door, the wood will fill the columns in
the middle of the camera image, thereby our algorithm just processes the forty
columns in the middle. Therefore, from an original image of 120
×
160, it only
considers a block of 60
×
40 from the segmented image.
Fig. 3.
Original and segmented images.
Search WWH ::

Custom Search