Information Technology Reference
In-Depth Information
Application
Fault tolerance techniques
User interfaces
QoS
requirements
Policy define
interface
Retrying
Checkpointing
Replication
Replication with
checkpointing
Workflow
...
Attributes analysis
Job
management
Data
management
Information
management
Decision making
Policy executor
Policy maker
Services
Policy engine
FIGURE 4.13
Overview of DRIC.
Also the user can specify the failure-handling policy with the policy
dei nition interface, and the policy engine carries it out.
4.5.4.2
Application-Level Fault-Tolerance Techniques
In this section the task-level fault-tolerance techniques to handle task
failures are reviewed.
•
Retrying: This is a simple and obvious failure-handling technique,
with which the system retries to run the task on the same resources
when a failure is detected [68,69]. Generally, the user or the system
specii es the maximum number of retries and the intervals
between the retries. After these retries, if the failure still exists,
the system prompts an error, and the user or the system should
provide other failure-handling methods to i nish the task.
Replication: The basic idea of replication is to have replicas of tasks
•
running on different resources, so that as long as not all replicated
tasks crash, the execution of the associated activity would succeed.
The failure detector detects these replicated tasks during the task
execution and the policy executor kills other replicated tasks when
one of them i nishes with the appropriate result.
Checkpointing: This has been widely studied in distributed
•
systems. Traditionally, for a single system, checkpointing can be
realized at three levels: kernel level, library level, and application















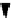






Search WWH ::

Custom Search