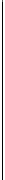Database Reference
In-Depth Information
ID A1 A2 A3 A4 A5
1
2
3
4
5
6
ID A1 A2 A3 A4 A5
1
3
4
ID A1 A2 A3 A4 A5
1
2
3
4
5
6
ID A1 A2 A3 A4 A5
2
5
6
ID A1 A2
1
2
3
4
5
6
ID A3 A4 A5
1
2
3
4
5
6
BILD 2.7
Horizontale und vertikale Partitionierung
etwa die CPU, Speicher oder Festplatten, einzige Ausnahme ist das Netzwerk.
Geograische
Verteilung
kann sich hierbei auf verschiedene Server Racks, Räume oder Gebäude bezie-
hen, kann aber auch die Verteilung auf Systeme in verschiedenen Städten oder Ländern
bedeuten. In der Regel schließt diese Art der Verteilung auch die Verteilung auf separate
Datenbanken ein, die am jeweiligen Standort geplegt werden.
Dies bringt bei der Datenintegration verschiedene Probleme mit sich. Zunächst muss klar
sein, wo sich welche Daten beinden. Bei physischer Verteilung steht man vor der Heraus-
forderung, dass der genaue physische Speicherort der benötigten Daten bekannt sein muss
und dass zu allen Systemen in irgendeiner Art und Weise eine Verbindung hergestellt wer-
den kann. Außerdem müssen die erforderlichen Zugriffe auf das System gewährleistet sein.
Dies ist nicht nur ein technisches , sondern oft auch ein juristisches Problem. Bei logischer
Verteilung müssen die Art der Partitionierung (horizontal, vertikal oder beides kombiniert)
sowie die Partitionierungskriterien genau bekannt sein, um den logischen Speicherort der
Daten zu identiizieren.
Liegen die Daten partitioniert in verschiedenen Schemas in unterschiedlichen Datenban-
ken auf unterschiedlichen Systemen, ist es kaum noch möglich diese mit einfachen SQL-
Abfragen zu erreichen. [LN07, S.52]. Mögliche Ansätze für die Überwindung derartiger Pro-
bleme werden u. a. in [LN07, S.173 ff.] ausführlich beschrieben.
Mitunter werden Daten lediglich repliziert und auf verschiedenen Systemen abgelegt, z. B.
weil an unterschiedlichen Standorten die gleichen Daten benötigt werden und ein lokaler
Zugriff gewünscht wird. Dies ist keine Verteilung im eigentlichen Sinne, sondern eine mehr
oder weniger kontrollierte redundante Datenhaltung. Um Inkonsistenzen durch lokale Än-
derungen zu verhindern ist in diesem Fall eine ständige, automatisierte Synchronisation
der replizierten mit den originären Daten erforderlich [Con97, S.44].
Doch auch bei kontrolliert und bewusst verteilten Daten besteht ein gewisses Risiko. Wer-
den verteilte Daten autonom verwaltet und fehlen einheitliche Richtlinien und Standards,
führt dies beinahe zwangsläuig zu
Heterogenität
, d. h. die Datenstrukturen und die Daten
selbst unterscheiden sich. Die sich daraus ergebenden Schwierigkeiten für die Integration
von verteilten Daten werden in Abschnitt 2.3.3 näher beschrieben.