Database Reference
In-Depth Information
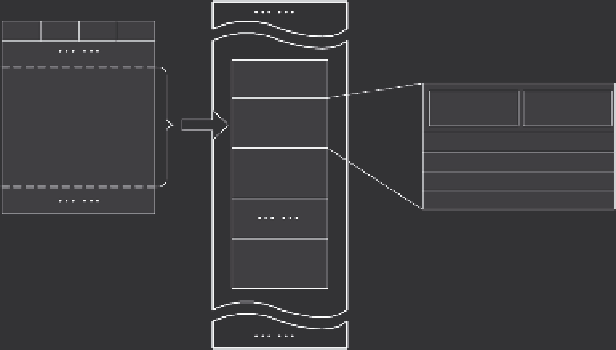
RCFile
Relation
ABCD
Row group
HDFS
block
101
102
103
104
105
111
112
113
114
115
121
122
123
124
105
131
132
133
134
135
16 bytes
sync
101,
111,
121,
131,
Metadata
header
Row group 1
102,
112,
122,
132,
103,
113,
123,
133,
104,
114,
124,
134,
105
115
125
135
Row group 2
Row group n
FIGURE 2.8
An example structure of
RCFile
. (From Y. He et al., RCFile: A fast and
space-efficient data placement structure in MapReduce-based warehouse systems, in
ICDE
,
pp. 1199-1208, 2011.)
during query execution. In particular, the metadata header section is compressed
using the
RLE
(Run Length Encoding) algorithm. The table data section is not com-
pressed as a whole unit. However, each column is independently compressed with the
Gzip
compression algorithm. When processing a row group, RCFile does not need to
fully read the whole content of the row group into memory. It only reads the meta-
data header and the needed columns in the row group for a given query, and thus, it
can skip unnecessary columns and gain the I/O advantages of a column-store. The
metadata header is always decompressed and held in memory until RCFile processes
the next row group. However, RCFile does not decompress all the loaded columns
and uses a lazy decompression technique where a column will not be decompressed
in memory until RCFile has determined that the data in the column will be really
useful for query execution.
The notion of
Trojan data layout
has been coined in [78], which exploits the exist-
ing data block replication in HDFS to create different Trojan layouts on a per-replica
basis. This means that rather than keeping all data block replicas in the same layout,
it uses
different
Trojan layouts for each replica, which is optimized for a different
subclass of queries. As a result, every incoming query can be scheduled to the most
suitable data block replica. In particular, Trojan layouts change the internal organi-
zation of a data block and not among data blocks. They co-locate attributes together
according to query workloads by applying a column grouping algorithm that uses
an interestingness measure that denotes how well a set of attributes speeds up most
or all queries in a workload. The column groups are then packed to maximize the
total interestingness of data blocks. At query time, an incoming MapReduce job is
transparently adapted to query the data block replica that minimizes the data access
time. The map tasks are then routed of the MapReduce job to the data nodes storing
such data block replicas.
Search WWH ::

Custom Search