Database Reference
In-Depth Information
Version
Column type
Compression scheme
File header
#Value per block (k)
Sync (optional)
Value 1
Value 2
…
Value k
Data block 1
Data block 2
Offset of block 1
Offset of block 2
Data block n
Block index
Indexed value
(optional)
File summary
Offset of block n
Starting value in block 1
Starting value in block 2
#Total records
#Blocks
Offset of block index
Offset of indexed value
Starting value in block n
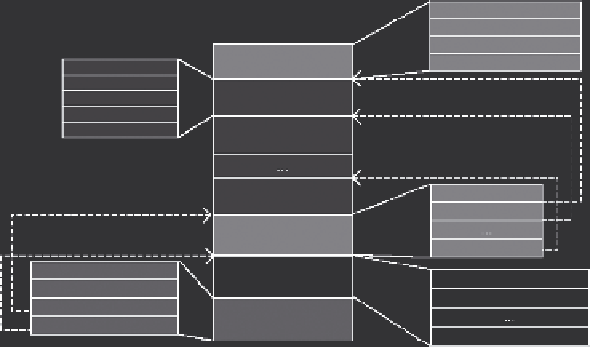
FIGURE 2.7
An example structure of
CFile
. (From Y. Lin et al., Llama: Leveraging
columnar storage for scalable join processing in the MapReduce framework, in
SIGMOD
Conference
, pp. 961-972, 2011.)
of columns, one of them is specified as the sorting column. Initially, when a new
table is imported into the system, a basic vertical group is created, which contains all
the columns of the table and sorted by the table's primary key by default. In addition,
based on statistics of query patterns, some auxiliary groups are dynamically created
or discarded to improve the query performance. The
Clydesdale
system [13,79], a
system that has been implemented for targeting workloads where the data fits a star
schema, uses
CFile
for storing its fact tables. It also relies on tailored join plans and
block iteration mechanism [140] for optimizing the execution of its target workloads.
RCFile
[63] (Record Columnar File) is another data placement structure that pro-
vides column-wise storage for Hadoop file system (HDFS). In RCFile, each table
is first stored as horizontally partitioned into multiple row groups where each row
group is then vertically partitioned so that each column is stored independently
(Figure 2.8). In particular, each table can have multiple HDFS blocks where each
block organizes records with the basic unit of a row group. Depending on the row
group size and the HDFS block size, an HDFS block can have only one or multiple
row groups. In particular, a row group contains the following three sections:
1. The
sync marker
, which is placed in the beginning of the row group and
mainly used to separate two continuous row groups in an HDFS block.
2. A metadata header, which stores the information items on how many
records are in this row group, how many bytes are in each column and how
many bytes are in each field in a column.
3. The table data section, which is actually a column-store where all the fields
in the same column are stored continuously together.
RCFile utilizes a column-wise data compression within each row group and pro-
vides a lazy decompression technique to avoid unnecessary column decompression
Search WWH ::

Custom Search