Database Reference
In-Depth Information
Driver
Coordinator
Process
Fork
Communication
DFS file/chunks
Mapper
Mapper
Mapper
Mapper
Split
Split
Split
Split
Split
Reducer
Internal transfer
Reducer
DFS input/output
Remote transfer
Reducer
Merger
Output
Output
Output
Mapper
Mapper
Mapper
Mapper
Merger
Merger
Split
Reducer
Split
Split
Split
Split
Reducer
Reducer
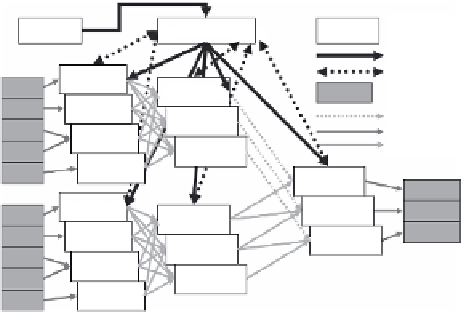
FIGURE 2.4
An overview of the map-reduce-merge framework. (From H. C. Yang et al.,
Map-reduce-merge: Simplified relational data processing on large clusters, in
SIGMOD
,
pp. 1029-1040, 2007.)
pair (
k
1,
v1) into a list of intermediate key/value pairs [(
k
2,
v2)]. The reduce function
aggregates the list of values [
v2] associated with
k
2 and produces a list of values
[
v
3] that are also associated with
k
2. Note that inputs and outputs of both functions
belong to the same lineage (α). Another pair of map and reduce functions produce the
intermediate output (
k
3, [
v
4]) from another lineage (β).
Based on keys
k
2 and
k
3,
the
merge function combines the two reduced outputs from different lineages into a list
of key/value outputs [(
k
4,
v
5)]. This final output becomes a new lineage (γ). If α = β,
then this merge function does a self-merge, which is similar to self-join in relational
algebra. The main differences between the processing model of this framework and
the original MapReduce is the production of a key/value list from the reduce function
instead of just that of values. This change is introduced because the merge function
requires input data sets to be organized (partitioned, then either sorted or hashed) by
keys and these keys have to be passed into the function to be merged. In the origi-
nal framework, the reduced output is final. Hence, users pack whatever is needed
in [
v
3]
while passing
k
2 for the next stage is not required. Figure 2.5 illustrates a
sample execution of the map-reduce-merge framework. In this example, there are
two data sets
employee
and
department
, where employee's key attribute is
emp-id
and the department's key is
dept-id
. The execution of this example query aims to
join these two data sets and compute employee bonuses. On the left-hand side of
Figure 2.5, a mapper reads employee entries and computes a bonus for each entry. A
reducer then sums up these bonuses for every employee and sorts them by
dept-id
,
then
emp-id
. On the right-hand side, a mapper reads department entries and com-
putes bonus adjustments. A reducer then sorts these department entries. At the end,
a merger matches the output records from the two reducers on
dept-id
and applies a
department-based bonus adjustment on employee bonuses. Yang et al. [37] have also
proposed an approach for improving the map-reduce-merge framework by add-
ing a new primitive called
traverse
. This primitive can process index file entries