Database Reference
In-Depth Information
User
program
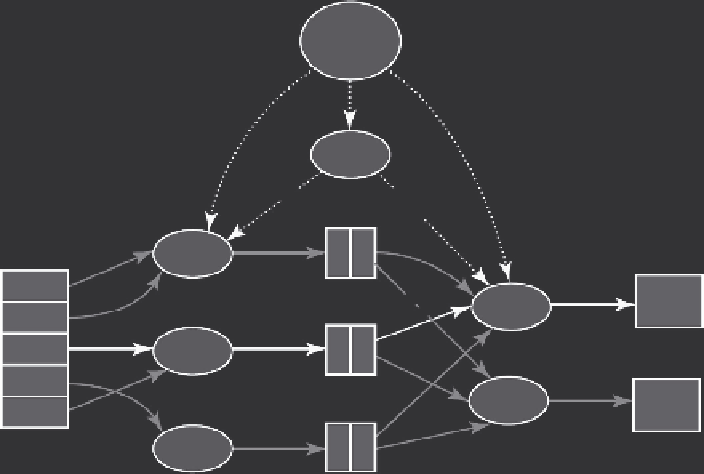
(1) fork
(1) fork
(1) fork
Master
(2)
assign
map
(2)
assign
reduce
Worker
Split 0
Split 1
Split 2
Split 3
Split 4
(6) write
Output
file 0
Worker
(4) local write
(3) read
Worker
Output
file 1
Worker
Worker
Input files
Map phase
Intermediate files
(on local disk)
Reduce phase
Output
files
FIGURE 2.2
An overview of the flow of execution a MapReduce Operation. (From J. Dean
and S. Ghemawat, MapReduce: Simplified data processing on large clusters, in
OSDI
,
pp. 137-150, 2004.)
by other workers. Completed map tasks are re-executed on a task failure because
their output is stored on the local disk(s) of the failed machine and is therefore inac-
cessible. Completed reduce tasks do not need to be re-executed since their output is
stored in a global file system.
2.3 EXTENSIONS AND ENHANCEMENTS OF
THE MapReduce FRAMEWORK
In practice, the basic implementation of the MapReduce is very useful for handling
data processing and data loading in a heterogeneous system with many different stor-
age systems. Moreover, it provides a flexible framework for the execution of more
complicated functions than that can be directly supported in SQL. However, this
basic architecture suffers from some limitations. Dean and Ghemawa [45] reported
about some possible improvements that can be incorporated into the MapReduce
framework. Examples of these possible improvements include the following:
•
MapReduce should take advantage of natural indices whenever possible.
•
Most MapReduce output can be left unmerged since there is no benefit of
merging them if the next consumer is just another MapReduce program.
•
MapReduce users should avoid using inefficient textual formats.
Search WWH ::

Custom Search