Database Reference
In-Depth Information
a timely manner. Section 14.5 discusses using the size information for combating
abuse. Section 14.6 reviews the related work, and we conclude in Section 14.7.
14.2 IP SIZE: CHALLENGES AND APPROACH
In [19], the sizes of the IPs were defined based on two dimensions: application and
time. Each IP has a specific size for each application, depending on the number of
human users of this application. The query size of an IP is the number of humans
querying a search engine for example, Google, which may differ from the number of
users clicking ads. Thus, sizes should be estimated using the log files of the applica-
tion whose activity is subject to estimation.
The second dimension for defining the size is time. The number of human users
behind an IP changes over time, for instance, when the IP observes a flash crowd,
i.e., an unexpected surge in usage, or when it gets reassigned to households and/
or companies. The size estimates should be issued frequently enough to cope with
these frequent changes. This calls for a short estimation time period. On the other
hand, the estimation period should be long enough to yield enough IP coverage, and
enough traffic per IP to produce statistically sound estimates.
14.2.1 e
stimation
C
hallenges
anD
m
ethoDology
While estimating the sizes of individual IPs has ramifications on the security field,
the primary concern is violating the user privacy. The work at [19] preserves the
user privacy by estimating sizes of IPs using the application-level log files. First, the
application users are assumed to be only temporarily identified, for example, with
cookie IDs in the case of HTTP-based log files. Thus, no Personally Identifiable
Information, such as the name or the email address, is revealed. Second, no individ-
ual machines are tracked. Third, the framework uses application log data aggregated
at the IP level. Over 30% of dynamic IPs are reassigned every 1 to 3 days [27], and
thus an IP is considered a temporary identification of a user. Finally, the majority of
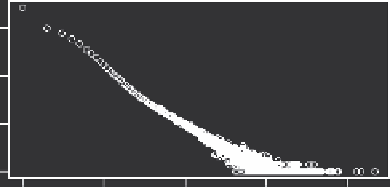
the users share IPs. This is illustrated in Figure 14.2, where 10M random IPs (from
Google ad click log files) are shared by 26.9M total estimated users.
Estimating sizes from the log files is not straightforward. Naïve counting of dis-
tinct user identifications, for example, cookie IDs or user agents (UAs), per IP fails
1e+06
1e+04
1e+02
1e+00
1
10
100
1000
10,000
Estimated distinct count (user IDs)
FIGURE 14.2
The estimated sizes of 10M random IPs.
Search WWH ::

Custom Search