Database Reference
In-Depth Information
graph is partitioned into
k
partitions using a hash-based random algorithm [47], with
k
being much larger than the number of cluster machines. A partition in GraphLab
is called an
atom
. GraphLab does not store the actual vertices and edges in atoms,
but
commands
to generate them. In addition to commands, GraphLab maintains in
each atom some information about the atom's neighboring vertices and edges. This
is denoted in GraphLab as
ghosts
. Ghosts are used as a caching capability for effi-
cient adjacent data accessibility. In the second phase of the two-phase partitioning
strategy, GraphLab stores the connectivity structure and the locations of atoms in
an
atom index file
referred to as
metagraph
. The atom index file encompasses
k
vertices (with each vertex corresponding to an atom) and edges encoding connectiv-
ity among atoms. The atom index file is split uniformly across the cluster machines.
Afterward, atoms are loaded by cluster machines and each machine constructs its
partitions by executing the commands in each of its assigned atoms. By generating
partitions via executing commands in atoms (and
not
directly mapping partitions to
cluster machines), GraphLab allows future changes to graphs to be simply appended
as additional commands in atoms without needing to repartition the entire graphs.
Furthermore, the same graph atoms can be reused for different sizes of clusters by
simply re-dividing the corresponding atom index file and re-executing atom com-
mands (i.e., only the second phase of the two-phase partitioning strategy is repeated).
In fact, GraphLab has adopted such a graph partitioning strategy with the
elasticity
of clouds being in mind. Clearly, this improves upon the
direct
and
non-elastic
hash-
based partitioning strategy adopted by Pregel. Specifically, in Pregel, if graphs or
cluster sizes are altered after partitioning, the entire graphs need to be repartitioned
prior to processing.
1.5.5 s
ymmetriCal
anD
a
symmetriCal
a
rChiteCtural
m
oDels
From architectural and management perspectives, a distributed program can be typi-
cally organized in two ways,
master/slave
(or
asymmetrical
) and
peer-to-peer
(or
symmetrical
) (see Figure 1.12). There are other organizations, such as hybrids of
asymmetrical and symmetrical, which do exist in literature [71]. For the purpose of
our chapter, we are only concerned with the master/slave and peer-to-peer organiza-
tions. In a master/slave organization, a central process known as the
master
handles
Master
Master
(Not necessary)
Slave
Slave
Slave
Slave
Slave
Slave
(a)
(b)
FIGURE 1.12
(a) A master/slave organization. (b) A peer-to-peer organization. The master
in such an organization is optional (usually employed for monitoring the system and/or inject-
ing administrative commands).






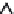

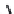



















Search WWH ::

Custom Search