Database Reference
In-Depth Information
“contents”:
“anchor:cnnsi.com”
“anchor:my.look.ca”
“<html>...”
t
3
t
9
“CNN.com”
t
8
“<html>...”
“CNN”
“com.cnn.www”
t
5
“<html>...”
t
6
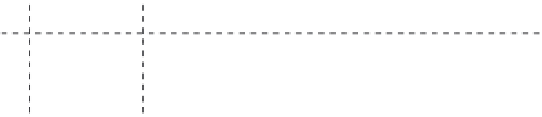
FIGURE 9.2
Sample Bigtable structure. (From F. Chang et al.,
ACM Trans. Comput. Syst.
,
26, 20 08.)
by row key where the row range for a table is dynamically partitioned. Each row
range is called a
tablet
, which represents the unit of distribution and load balancing.
Thus, reads of short row ranges are efficient and typically require communication
with only a small number of machines. Bigtables can have an unbounded number of
columns that are grouped into sets called
column families
. These column families
represent the basic unit of access control. Each cell in a Bigtable can contain multiple
versions of the same data that are indexed by their timestamps. Each client can flex-
ibly decide the number of
n
versions of a cell that need to be kept. These versions are
stored in decreasing timestamp order so that the most recent versions can be always
read first.
The Bigtable API provides functions for creating and deleting tables and column
families. It also provides functions for changing cluster, table, and column family
metadata, such as access control rights. Client applications can write or delete values
in Bigtable, look up values from individual rows, or iterate over a subset of the data
in a table. At the transaction level, Bigtable supports only
single-row
transactions,
which can be used to perform atomic read-modify-write sequences on data stored
under a single row key (i.e., no general transactions across row keys).
At the physical level, Bigtable uses the distributed Google File System (GFS)
[33] to store log, and data files. The Google
SSTable
file format is used internally
to store Bigtable data. An SSTable provides a persistent, ordered immutable map
from keys to values, where both keys and values are arbitrary byte strings. Bigtable
relies on a distributed lock service called
Chubby
[17], which consists of five active
replicas, one of which is elected to be the
master
and actively serves requests. The
service is live when a majority of the replicas are running and can communicate
with each other. Bigtable uses Chubby for a variety of tasks such as (1) ensuring
that there is at most one active master at any time, (2) storing the bootstrap location
of Bigtable data, (3) storing Bigtable schema information and to the access control
lists. The main limitation of this design is that if Chubby becomes unavailable for an
extended period of time, the whole Bigtable becomes unavailable. At the runtime,
each Bigtable is allocated to one master server and many tablet servers, which can be
dynamically added (or removed) from a cluster based on the changes in workloads.
The master server is responsible for assigning tablets to tablet servers, balancing tablet-
server load, and garbage collection of files in GFS. In addition, it handles schema
changes such as table and column family creations. Each tablet server manages a set
of tablets. The tablet server handles read and write requests to the tablets that it has
loaded, and also splits tablets that have grown too large.

















Search WWH ::

Custom Search