Database Reference
In-Depth Information
V
0
V
1
V
2
01 00 10
B
0,1
B
0,2
×
×
×
010111
110010
010101
000010
010101
111010
0
1
0
0
1
0
01
11
01
00
01
11
01
00
01
00
01
10
11
B
0,0
V
0
10
01
10
01
10
B
1,0
×
=
+
+
V
1
B
2,0
V
2
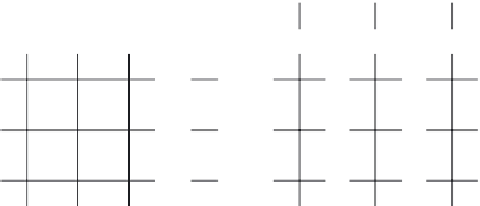
FIGURE 8.2
GIM-V
BL using 2 × 2 blocks.
B
i,j
represents a matrix block and
v
i
represents
a vector block. The matrix and vector are joined block-wise, not element-wise.
is
row ol
)
. Similarly,
(
,
,
row ol
,
,
mval
,
,,
rowcol
,
,
mval
block
block
elem
elem
elem
elem
elem
elem
1
1
1
k
k
k
the format of a vector block with
k
nonzero elements is
id
(
,
id
,
vval
,
,
block
elem
elem
1
1
id
,
)
. Only blocks with at least one nonzero elements are saved to disk.
This block encoding forces nearby edges in the adjacency matrix to be closely located;
it is different from Hadoop's default behavior, which does not guarantee co-locating
them. After grouping,
GIM-V
is performed on blocks, not on individual elements.
GIM-V
BL is illustrated in Figure 8.2.
In Section 8.5, we observe that
GIM-V
BL is at least 5 times faster than
GIM-V
BASE. There are two main reasons for this speedup.
vval
elem
elem
k
k
•
Sorting Time
: Block encoding decreases the number of items to be sorted
in the shuffling stage of Hadoop. We observe that one of the main efficiency
bottlenecks in Hadoop is its shuffling stage where network transfer, sorting,
and disk I/O take place.
•
Compression
: The size of the data decreases significantly by converting edges
and vectors to block format. The reason is that in
GIM-V
BASE, we need 2 × 4 =
8 bytes to save each (srcid, dstid) pair. However in
GIM-V
BL we can specify
each
block
using a block row id and a block column id with two 4-byte inte-
gers and refer to elements inside the block using 2 × log
b
bits. This is possible
because we can use log
b
bits to refer to a row or column inside a block. By this
block method, we decrease the edge file size. For instance, using block encod-
ing, we are able to decrease the size of the Yahooweb graph more than 50%.
8.4.3
GIM-V
Cl: Cl:
lustereD
e
Dges
We use co-clustering heuristics, see [44] as a preprocessing step to obtain a better
clustering of the edge set. Figure 8.3 illustrates the concept. The preprocessing step
needs to be performed only once. If the number of iterations required for the execu-
tion of an algorithm is large, then it is beneficial to perform this preprocessing step.
Notice that we have two variants of
GIM-V
:
GIM-V
CL and
GIM-V
BL-CL, which
are
GIM-V
BASE and
GIM-V
BL with clustered edges, respectively.









Search WWH ::

Custom Search