Database Reference
In-Depth Information
(a)
2500
200
2000
150
1500
100
1000
50
500
0
0
dq
0
dq
1
dq
2
dq
3
dq
4
dq
0
dq
1
dq
2
dq
3
dq
4
SHARD
Pig-Def
NTGA
(b)
2500
Pig-Def
NTGA
2000
1500
58%
55%
1000
54.8%
52.8%
500
0
BSBM-250k
(22 GB)
BSBM-500k
(43 GB)
BSBM-750k
(66 GB)
BSBM-1000k
(86 GB)
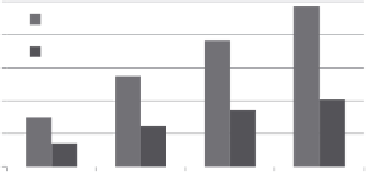
FIGURE 6.15
(a) A comparative evaluation of the three approaches (SHARD, Pig-Def,
NTGA) for the queries with repeated properties. (b) Scalability study of scan-sharing
approach for query
dq
4 with increasing sizes of RDF graphs.
I/O compared with other two approaches. Further, the execution time in SHARD
increases as the number of triple patterns increases from 8 to 12 in
dq
0 to
dq
4,
respectively. Pig-Def shows relatively better performance compared with SHARD
because the number of MR jobs for star join is mainly affected by the number of
star patterns in the queries. However, the amount of HDFS reads for all queries in
Pig-Def is still larger than the one in NTGA because the DupPs are scanned and pro-
cessed in BOTH the star-join cycles (MR1 and MR2 among 3 MR jobs) in Pig-Def,
which results in an increasing amount of HDFS bytes read as the number of DupPs
increase. In NTGA, it is observed that the execution time and the amount of HDFS
reads do not change much with varying numbers of DupPs because the grouping-
based star-join computation approach in NTGA enables a scan sharing for DupPs
while processing star subpatterns containing DupPs.
6.8.2.3 Varying Size of RDF Graphs
Figure 6.15b shows a comparative evaluation of the two approaches (Pig-Def and
NTGA) with increasing number of RDF triples. The NTGA approach scales well
with a performance gain of 52% to 58% ranging over BSBM-250k to BSBM-1000k
data sizes, respectively. The gain varies because the number of triples containing
repeated properties is not linearly increased when increasing the size of the data
sets.

























































Search WWH ::

Custom Search