Database Reference
In-Depth Information
Q2
Q2 opt
Q2 opt+part
Q6 opt
Q6 opt+part
9
18
16
8
7
14
12
6
5
10
8
4
3
6
4
2
1
2
0
0
0
200
400
600
800
1000
1200
1400
1600
0
200 00
600 00
1000
1200
1400
1600
(a)
(c)
SP
2
Bench (# triples in million)
SP
2
Bench (# triples in million)
Q2
Q2 opt
Q2 opt+part
Q6 opt (800 M)
Q6 opt+part (800 M)
Q6 opt+part (1600 M)
HDFS Bytes Read HDFS Bytes WrittenReduce Shue Bytes
in GB (1600 million RDF triples)
HDFS Bytes Read
HDFS Bytes Written
Reduce Shue
Bytes
in GB (800/1600 million RDF triples)
(b)
(d)
Q3a
Q3a opt
Q3a opt+part
Q3b
Q3b opt
Q3b opt+part
3:30
3:30
3:00
3:00
2:30
2:30
2:00
2:00
1:30
1:30
1:00
1:00
0:30
0:30
0:00
0:00
0
200
400
600
800
1000
1200
1400
1600
0 00
400 00
8001000120014001600
(e)
(g)
SP
2
Bench (# triples in million)
SP
2
Bench (# triples in million)
Q3a
Q3a opt
Q3a opt+part
Q3b
Q3b opt
Q3b opt+part
HDFS Bytes Read
Reduce Shue Bytes
HDFS Bytes Written
HDFS Bytes Read
Reduce Shue Bytes
HDFS Bytes Written
in GB (1600 million RDF triples)
in GB (1600 million RDF triples)
(f)
(h)
FIGURE 5.5
Runtimes and IO costs for SP
2
Bench queries Q2 (a+b), Q6 (c+d), Q3a (e+f),
and Q3b (g+h).
OPTIONAL), making the query especially challenging. Only when using a vertical
partitioned data set, the capacity of our cluster was sufficient for executing Q6 with
1600 million triples. Without vertical partitioning, there was not enough local and
distributed disk space. To overcome such situation we could make use of the horizon-
tal scalability of MapReduce and simply add more machines to the cluster.
Q6. Return, for each Year, All Publications of Persons
That Have Not Published in Years Before
SELECT ?yr ?name ?doc
WHERE {
?class rdfs:subClassOf foaf:Document.
?doc rdf:type ?class.
?doc dcterms:issued ?yr.
?doc dc:creator ?author.










































































































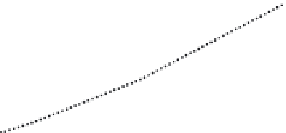



















































Search WWH ::

Custom Search