Database Reference
In-Depth Information
Contraction phase.
To evaluate the contraction phase, we run two versions of
Incoop, a version that only memoizes the output of an entire reduce task, and the full
design that includes the contraction phase. We identify these two versions as
Task
and
Contraction
. Figure 4.6 compares the work and time speedup of the two
versions using an application of each class (
CoMatrix
is data-intensive and
KNN
is CPU-intensive). The contraction phase does not change the performance of
KNN
but significantly improves the performance of
CoMatrix
. This is related to the fact
that the reduce phase in
KNN
performs a simple computation and thus has little to
gain from the contraction phase. Given this fact, it is noteworthy that the contraction
phase did not add significant overhead.
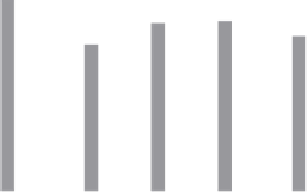
Scheduler modification.
We now evaluate the effectiveness of the memoization-
aware scheduler. In Figure 4.7, we compare the time to run the various applications
in Incoop using the new and the original Hadoop scheduler. The Y-axis presents
the total running time normalized to the time using the Hadoop scheduler. The
memoization-aware scheduler cuts the running time by 30% for data-intensive appli-
cations and almost 15% for CPU-intensive applications. This highlights the impor-
tance of this design aspect.
4.6.7 o
verheaDs
Next we evaluate the price that is paid for the gains we showed in the previous sec-
tion, namely the overheads introduced by Incoop during the initial run, and the space
requirements for storing memoized results. The results are shown in Figure 4.8.
Performance overhead.
Figure 4.8a depicts the performance overhead for the
first run for the
Task
and the
Contraction
variants as described before. We
stress that these overheads are a one-time cost that can lead to substantial gains
in subsequent runs. The overhead varies from 5% to 22% and is lower for CPU-
intensive applications (
K-Means
and
KNN
), since the time to compute over the data
dominates the time to transfer this data to be stored. For data-intensive applications
1.4
Hadoop scheduler
Incoop scheduler
1.2
1
0.8
0.6
0.4
0.2
0
K-Means WordCount
KNN
CoMatrix BiCount
Applications
FIGURE 4.7
Effectiveness of scheduler optimizations.















Search WWH ::

Custom Search