Database Reference
In-Depth Information
(a)
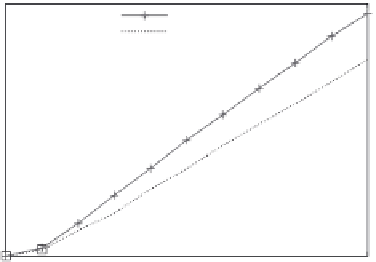
3000
MapReduce
iMapReduce
2500
2000
1500
1000
500
0
0
2
4
6
8
10
Iterations
(b)
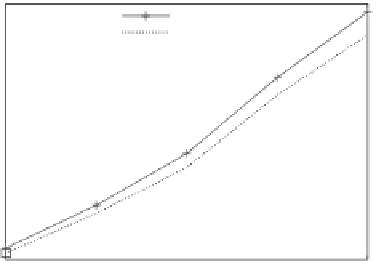
9000
MapReduce
iMapReduce
8000
7000
6000
5000
4000
3000
2000
1000
1
2
3
4
5
Iterations
FIGURE 3.6
The running time of K-means (a) and MPI (b).
3.6 RELATED WORK
MapReduce, as a popular distributed framework for data-intensive computation,
has gained considerable attention over the past few years [4]. The framework has
been extended for diverse application requirements. MapReduce Online [3] pipelines
map/reduce operations and performs online aggregation to support efficient online
queries, which directly inspires our work.
To support implementing large-scale iterative algorithms, there are a number of
studies proposing new distributed computing frameworks for iterative processing
[2,5,8-10,13,14,16,17,20].
A class of these efforts targets on managing static data efficiently. Design pat-
terns for running efficient graph algorithms in MapReduce have been introduced in
[10]. They partition the static graph adjacency list into
n
parts and pre-store them on
DFS. However, since the MapReduce framework arbitrarily assigns reduce tasks to
workers, accessing the graph adjacency list can involve remote reads. This cannot
guarantee local access to the static data. HaLoop [2] is proposed aiming at iterative



















































Search WWH ::

Custom Search