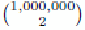Database Reference
In-Depth Information
3.4 Locality-Sensitive Hashing for Documents
Even though we can use minhashing to compress large documents into small signatures
and preserve the expected similarity of any pair of documents, it still may be impossible to
find the pairs with greatest similarity efficiently. The reason is that the number of pairs of
documents may be too large, even if there are not too many documents.
EXAMPLE
3.9 Suppose we have a million documents, and we use signatures of length 250.
Then we use 1000 bytes per document for the signatures, and the entire data fits in a giga-
byte - less than a typical main memory of a laptop. However, there are or half a
trillion pairs of documents. If it takes a microsecond to compute the similarity of two sig-
natures, then it takes almost six days to compute all the similarities on that laptop.
□
If our goal is to compute the similarity of every pair, there is nothing we can do to reduce
the work, although parallelism can reduce the elapsed time. However, often we want only
the most similar pairs or all pairs that are above some lower bound in similarity. If so, then
we need to focus our attention only on pairs that are likely to be similar, without investigat-
ing every pair. There is a general theory of how to provide such focus, called
locality-sens-
itive hashing
(LSH) or
near
-
neighbor search
. In this section we shall consider a specific
form of LSH, designed for the particular problem we have been studying: documents, rep-
resented by shingle-sets, then minhashed to short signatures. In
Section 3.6
we present the
general theory of locality-sensitive hashing and a number of applications and related tech-
niques.
3.4.1
LSH for Minhash Signatures
One general approach to LSH is to “hash” items several times, in such a way that similar
items are more likely to be hashed to the same bucket than dissimilar items are. We then
consider any pair that hashed to the same bucket for any of the hashings to be a
candidate
pair
. We check only the candidate pairs for similarity. The hope is that most of the dissim-
ilar pairs will never hash to the same bucket, and therefore will never be checked. Those
dissimilar pairs that do hash to the same bucket are
false positives
; we hope these will be
only a small fraction of all pairs. We also hope that most of the truly similar pairs will hash
to the same bucket under at least one of the hash functions. Those that do not are
false neg-
atives
; we hope these will be only a small fraction of the truly similar pairs.
If we have minhash signatures for the items, an effective way to choose the hashings is
to divide the signature matrix into
b
bands consisting of
r
rows each. For each band, there is
a hash function that takes vectors of
r
integers (the portion of one column within that band)