Database Reference
In-Depth Information
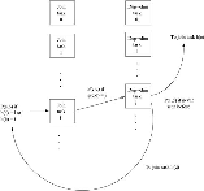
Figure 2.7
suggests how we could organize recursive tasks to perform this computation.
There are two kinds of tasks:
Join tasks
and
Dup-elim tasks
. There are
n
Join tasks, for
some
n
, and each corresponds to a bucket of a hash function
h
. A path tuple
P
(
a, b
), when
it is discovered, becomes input to two Join tasks: those numbered
h
(
a
) and
h
(
b
). The job
of the
i
th Join task, when it receives input tuple
P
(
a, b
), is to find certain other tuples seen
previously (and stored locally by that task).
Figure 2.7
Implementation of transitive closure by a collection of recursive tasks
(1) Store
P
(
a, b
) locally.
(2) If
h
(
a
) =
i
then look for tuples
P
(
x, a
) and produce output tuple
P
(
x, b
).
(3) If
h
(
b
) =
i
then look for tuples
P
(
b, y
) and produce output tuple
P
(
a, y
).
Note that in rare cases, we have
h
(
a
) =
h
(
b
), so both (2) and (3) are executed. But generally,
only one of these needs to be executed for a given tuple.
There are also
m
Dup-elim tasks, and each corresponds to a bucket of a hash function
g
that takes two arguments. If
P
(
c, d
) is an output of some Join task, then it is sent to Dup-
elim task
j
=
g
(
c, d
). On receiving this tuple, the
j
th Dup-elim task checks that it had not
received it before, since its job is duplicate elimination. If previously received, the tuple
is ignored. But if this tuple is new, it is stored locally and sent to two Join tasks, those
numbered
h
(
c
) and
h
(
d
).
Every Join task has
m
output files - one for each Dup-elim task - and every Dup-elim
task has
n
output files - one for each Join task. These files may be distributed according
to any of several strategies. Initially, the
E
(
a, b
) tuples representing the arcs of the graph
are distributed to the Dup-elim tasks, with
E
(
a, b
) being sent as
P
(
a, b
) to Dup-elim task
g
(
a, b
). The Master can wait until each Join task has processed its entire input for a round.
Then, all output files are distributed to the Dup-elim tasks, which create their own output.
That output is distributed to the Join tasks and becomes their input for the next round. Al-
ternatively, each task can wait until it has produced enough output to justify transmitting its
output files to their destination, even if the task has not consumed all its input.
□