Database Reference
In-Depth Information
2.4.1
Workflow Systems
Two experimental systems called Clustera from the University of Wisconsin and Hyracks
from the University of California at Irvine extend MapReduce from the simple two-step
workflow (the Map function feeds the Reduce function) to any collection of functions, with
an acyclic graph representing workflow among the functions. That is, there is an acyclic
flow graph
whose arcs
a
→
b
represent the fact that function
a
's output is input to function
b
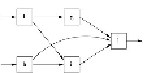
. A suggestion of what a workflow might look like is in
Fig. 2.6
. There, five functions,
f
through
j
, pass data from left to right in specific ways, so the flow of data is acyclic and no
task needs to provide data out before its input is available. For instance, function
h
takes its
input from a preexisting file of the distributed file system. Each of
h
's output elements is
passed to at least one of the functions
i
and
j
.
Figure 2.6
An example of a workflow that is more complex than Map feeding Reduce
In analogy to Map and Reduce functions, each function of a workflow can be executed
by many tasks, each of which is assigned a portion of the input to the function. A master
controller is responsible for dividing the work among the tasks that implement a function,
usually by hashing the input elements to decide on the proper task to receive an element.
Thus, like Map tasks, each task implementing a function
f
has an output file of data destined
for each of the tasks that implement the successor function(s) of
f
. These files are delivered
by the Master at the appropriate time - after the task has completed its work.
The functions of a workflow, and therefore the tasks, share with MapReduce tasks the
important property that they only deliver output after they complete. As a result, if a task
fails, it has not delivered output to any of its successors in the flow graph. A master con-
troller can therefore restart the failed task at another compute node, without worrying that
the output of the restarted task will duplicate output that previously was passed to some
other task.
Many applications of workflow systems such as Clustera or Hyracks are cascades of
MapReduce jobs. An example would be the join of three relations, where one MapReduce
job joins the first two relations, and a second MapReduce job joins the third relation with
the result of joining the first two relations. Both jobs would use an algorithm like that of
There is an advantage to implementing such cascades as a single workflow. For example,
the flow of data among tasks, and its replication, can be managed by the master controller,