Database Reference
In-Depth Information
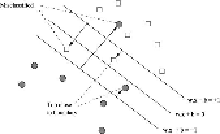
Figure 12.16
Points that are misclassified or are too close to the separating hyperplane incur a penalty; the amount of
the penalty is proportional to the length of the arrow leading to that point
Each bad point incurs a penalty when we evaluate a possible hyperplane. The amount
of the penalty, in units to be determined as part of the optimization process, is shown by
the arrow leading to the bad point from the hyperplane on the wrong side of which the bad
point lies. That is, the arrows measure the distance from the hyperplane
w
.
x
+
b
= 1 or
w
.
x
+
b
= −1. The former is the baseline for training examples that are supposed to be above the
separating hyperplane (because the label
y
is +1), and the latter is the baseline for points
that are supposed to be below (because
y
= −1).
We have many options regarding the exact formula that we wish to minimize. Intuitively,
we want ||
w
|| to be as small as possible, as we discussed in
Section 12.3.2
. But we also want
the penalties associated with the bad points to be as small as possible. The most common
form of a tradeoff is expressed by a formula that involves the term ||
w
||
2
/2 and another term
that involves a constant times the sum of the penalties.
To see why minimizing the term ||
w
||
2
/2 makes sense, note that minimizing ||
w
|| is the
same as minimizing any monotone function of ||
w
||, so it is at least an option to choose a
formula in which we try to minimize ||
w
||
2
/2. It turns out to be desirable because its deriv-
ative with respect to any component of
w
is that component. That is, if
w
= [
w
1
,
w
2
, . . .
,
w
d
], then ||
w
||
2
/2 is so its partial derivative
∂
/
∂w
i
is
w
i
. This situation makes sense
because, as we shall see, the derivative of the penalty term with respect to
w
i
is a constant
times each
x
i
, the corresponding component of each feature vector whose training example
incurs a penalty. That in turn means that the vector
w
and the vectors of the training set are
commensurate in the units of their components.
Thus, we shall consider how to minimize the particular function
(12.4)
The first term encourages small
w
, while the second term, involving the constant
C
that
must be chosen properly, represents the penalty for bad points in a manner to be explained
below. We assume there are
n
training examples (
x
i
,
y
i
) for
i
= 1, 2, . . . ,
n
, and
x
i
= [
x
i
1
,
x
i
2
,